Continued from previous article.
Why doesn’t the training/testing error improve after repeated epochs? The results of various attempts to answer this question are summarized below.
Galaxy image
Let’s see what galaxy images looks like in the Galaxy10 DECals Dataset.
# DataLoaderに格納されているイメージデータとラベルを表示
# 格納されているイメージデータは、正規化されている
import matplotlib.pyplot as plt
# 銀河形状名称(分類するクラス)
gala_classes = np.array(['Disturbed', 'Merging', 'Round Smooth', 'In-between RS', 'Cigar',
'Barred Spiral', 'Tight Spiral', 'Loose Spiral', 'Edge-on w/o Bulge', 'Edg-on w/t Bulge'])
n_img = 25 # 表示する画像数
gala_loader = DataLoader(train_dataset, batch_size=n_img, shuffle=True)
dataiter = iter(gala_loader) # イタレータ
images, labels = next(dataiter) # dataiter.next() はエラー
col = 5
row = (n_img + col -1)//col
plt.figure(figsize=(12,3*row))
for i in range(n_img):
ax = plt.subplot(row, col, i+1)
plt.imshow(np.transpose(images[i], (1, 2, 0))) # チャネルを一番最後に変更
ax.set_title(gala_classes[labels[i]])
ax.get_xaxis().set_visible(False)
ax.get_yaxis().set_visible(False)
plt.show()
The following image is obtained by executing the above code after the cell that obtained the train_dataset and test_dataset in Part 1.

The above images’ titles are as in the name of the dataset, although some of them are abbreviated due to space limitation, and their meanings are as follows: RS=Round Smooth, w/o=without, and w/t=with.
Even a human being cannot distinguish them. I bow down to the activities of Galaxy Zoo.
Rotate and flip data left and right
The following is the result of enabling the two lines that were commented out in transforms to increase the variation of the galaxy tilt.
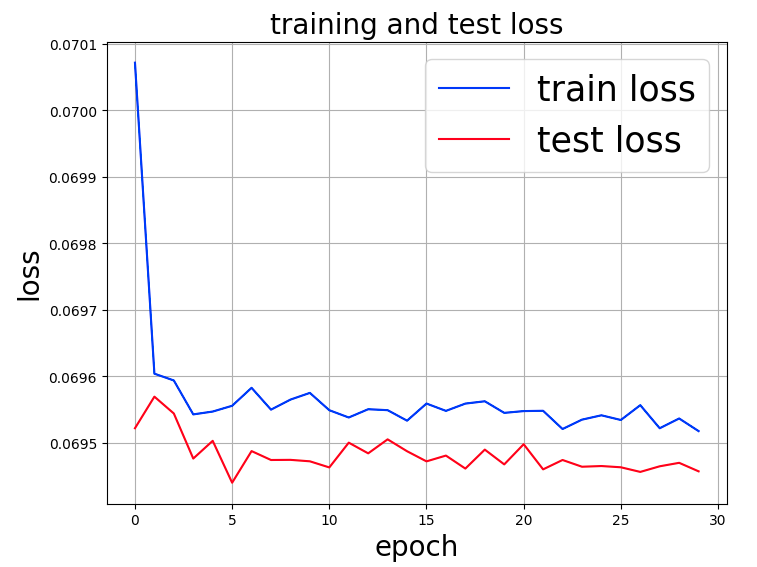
Still, the training/testing error remains flat over epochs, with no improvement.
Change the learning rate
I considered further data augmentaion by random cropping, noise addition, information loss, etc., but before that, let’s change the learning rate.
As shown below, the first cell of the “Training and Testing functions” section of the previous code was changed as follows to set a smaller learning rate. Speaking of which, I remembered that this article mentioned that they tried various learning rates and finally decided to set it to 0.00001. I remembered that the learning rate was finally set to 0.00001.
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
# 最適化手法を設定
optimizer = optim.Adam(model.parameters(), lr=0.00001)
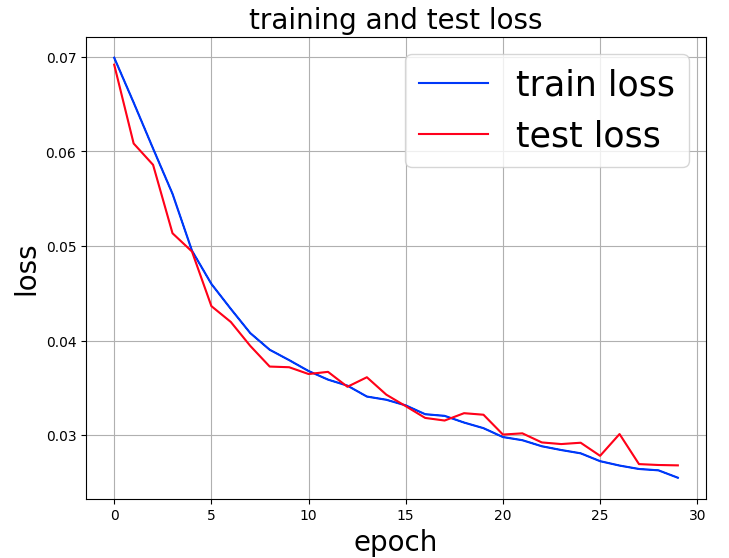
This time, we can see that both training/testing errors are improving as epochs are repeated. 30 epochs shows no tendency for over-training.
The time taken for the 30 epochs was 2,786 seconds (46 min 26 sec). Let’s try another half!
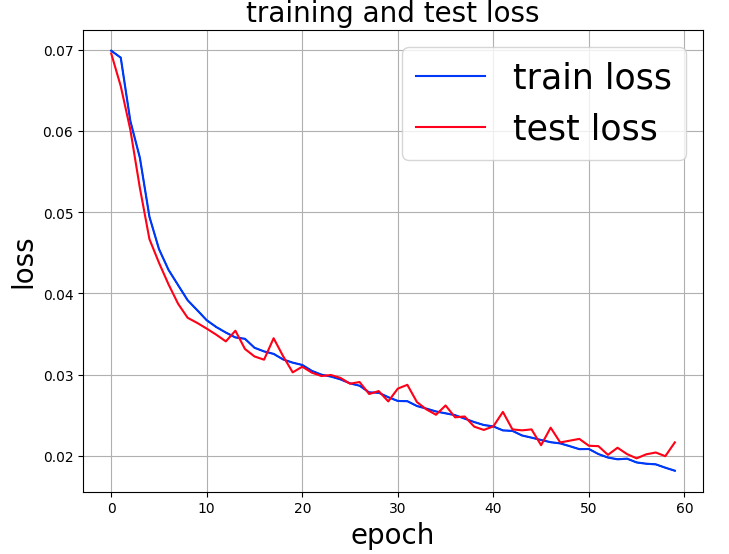
The time taken for 60 epochs was 5,574 seconds (92 minutes and 54 seconds).
It appears that after 50 or so epochs, the tendency of overlearning is starting to appear.
Summary of VGG16
In the case of VGG16, the most important point is to set the learning rate $lr$ to $0.00001$, and the loss value was about $0.02$ in about 50 epochs.
In next time, we will try using ResNet as the model.