Introduction.
In this article, we performed galaxy shape classification using the Vision Transformer (ViT) of Transformer’s adaptation to image processing. This time, we performed the same classification using a model already trained as a model for ViT.
Fine-tuning ViT
Replace the “Efficient Attention and Parameter Settings” section of the previous article with the following.
Load pre-trained model
model = timm.create_model('vit_small_patch16_224', pretrained=True, num_classes=10)
model.to(device)
That’s all.
No changes are made after the “Loss Function, Optimizer Settings” section in the previous article.
Running Results
The following are the results of fine tuning with the pre-trained model.
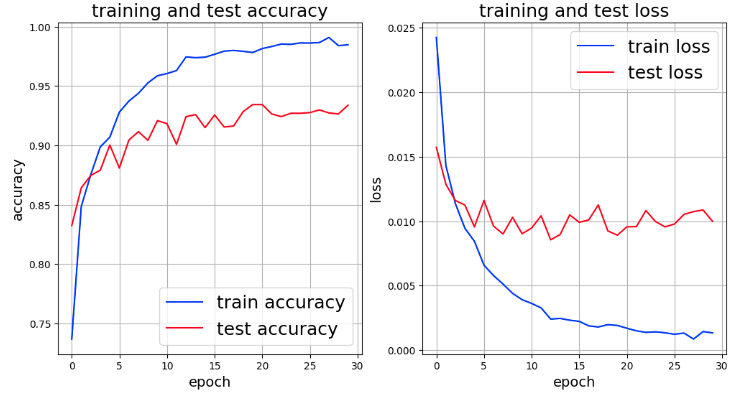
The above graph shows better values than “accuracy” and “loss” in ResNet, but it indicates overlearning. So, we would like to apply augmentation with transforms to the training image.
Randomly erase a part of the image and slightly strengthen the rotation angle.
Change transoforms as follows.
train_transforms = transforms.Compose([
transforms.CenterCrop(224),
transforms.RandomRotation(degrees=[-45, 45]),
transforms.RandomHorizontalFlip(p=0.3),
transforms.ToTensor(),
transforms.RandomErasing(scale=(0.1, 0.2), ratio=(0.8, 1.2), p=0.3),
])
The results of that run are as follows
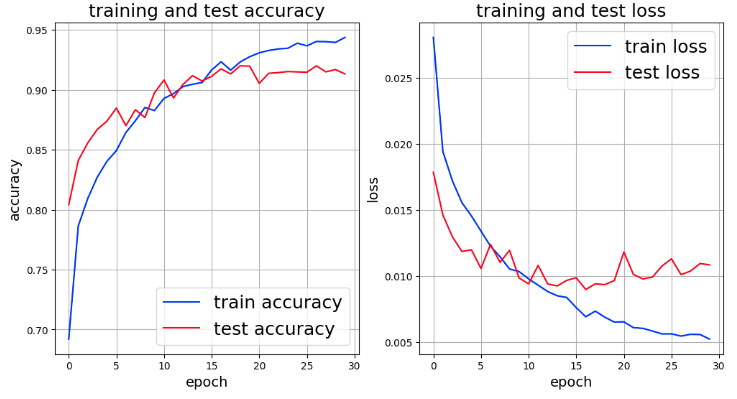
As for over-learning, although improvement is seen, it seems to be over-learning around the 15 epoch mark.
As shown below, the scale of RandomErasing was changed and the area to be deleted was slightly increased.
train_transforms = transforms.Compose([
transforms.CenterCrop(224),
transforms.RandomRotation(degrees=[-45, 45]),
transforms.RandomHorizontalFlip(p=0.3),
transforms.ToTensor(),
transforms.RandomErasing(scale=(0.1, 0.3), ratio=(0.8, 1.2), p=0.3),
])
A graph of the results follows. Overlearning seems to have improved considerably, but both “accuracy” and “loss” seem to have worsened when augmentation is applied to the data.
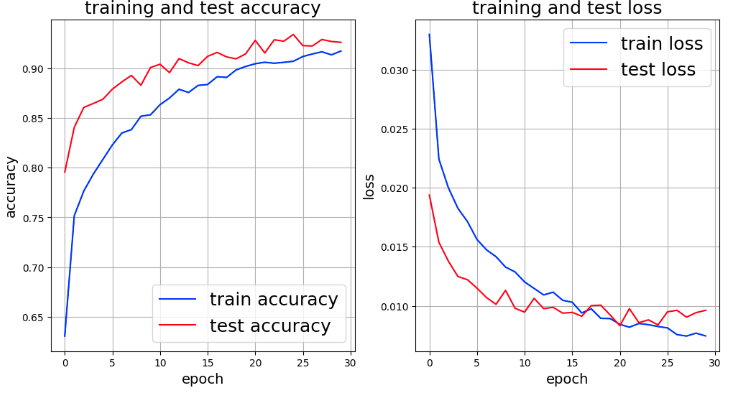
In the future, I would like to clarify the effect of augmentation of the training data in a more analytical way.
In doing so, I will try to analyze the results of the following confusion matrix.
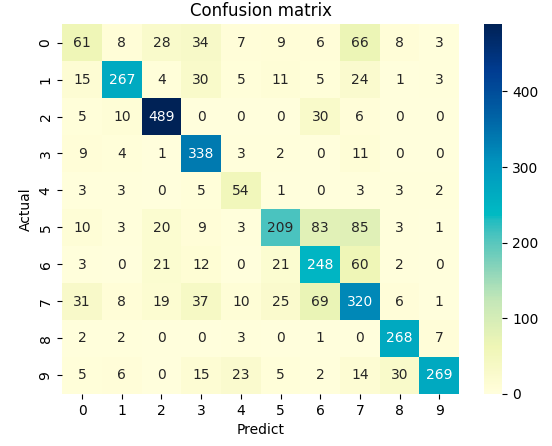
Translated with www.DeepL.com/Translator (free version)