Introduction
With Try Horovod in Docker, you can now use Horovod in your own environment (on-premises) and in a Docker environment. The next thing to do is to modify the training code running on a single server to apply it to distributed training using Horovod! For starters, I modified a relatively simple CNN code to allow distributed learning using Horovod, which is summarized in the following article.
Source
- original documentation - Document describing the steps to modify the training code to use Horovod with Pytorch.
The original CNN training code
For the base CNN training code (python code) to support Horovod, I decided to use the code I learned in Udemy before.
The title of Udemy is “Let’s learn image classification by AI! Pytorch+Golabo] from CNN Basics to Transformer Applications.”
In Section 2 of the above material, image classification using cifar10 data is implemented with CNN. In the following, only the parts that should be changed in Horovod are excerpted. For other parts, please refer to Udemy or the web.
DataLoader
# DataLoader setting
batch_size = 64
train_loader = DataLoader(cifar10_train, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(cifar10_test, batch_size=batch_size, shuffle=False)
Loss function, optimizer
from torch import optim
# Loss function
loss_fnc = nn.CrossEntropyLoss()
# Optimizer
optimizer = optim.Adam(net.parameters())
Change to support Horovod
Initialization part
Add the following initialization section to the beginning of the original CNN training code.
import torch
import horovod.torch as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per porcess)
if torch.cuda.is_available():
torch.cuda.set_device(hvd.local_rank())
DataLoader
The DataLoader part was changed as follows. I remember that it was an error that sampler and shuffle are incompatible (exclusive).
# DataLoader settings
batch_size = 64
#train_loader = DataLoader(cifar10_train, batch_size=batch_size, shuffle=True)
#test_loader = DataLoader(cifar10_test, batch_size=batch_size, shuffle=False)
# Partition dataset among workers using Distributed Sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(
cifar10_train, num_replicas=hvd.size(), rank=hvd.rank(), shuffle=True)
train_loader = DataLoader(cifar10_train, batch_size=batch_size,
sampler=train_sampler)
test_sampler = torch.utils.data.distributed.DistributedSampler(
cifar10_test, num_replicas=hvd.size(), rank=hvd.rank(), shuffle=False)
test_loader = DataLoader(cifar10_train, batch_size=batch_size,
sampler=test_sampler)
loss function, optimizer
The loss function, optimizer section should be modified as follows to wrap it for horovod.
from torch import optim
# loss function
loss_fnc = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(net.parameters())
# Add Horovod Distributed Optimizer
optimizer = hvd.DistributedOptimizer(optimizer,
named_parameters=net.named_parameters())
# Broadcast parameters & optimizer state from rank 0 to all other processes.
hvd.broadcast_parameters(net.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)
Use modified code with Horovod in Docker
Primary server
The modified python code was stored in an NFS area (/mnt/nfs/sample, I used NFS area, but local directories are fine). Then, when starting horovod, I mounted it as follows (-v /mnt/nfs/sample:/root/sample part) and made it available to the container.
$ sudo docker run -it --gpus all --net=host \
-v /mnt/nfs2/ssh:/root/.ssh \
-v /mnt/nfs/sample:/root/sample \
horovod/horovod:latest
In the container, the first, second, and third units were each started as follows. “time” is used to measure time.
# time horovodrun -np 1 -H localhost:1 python cifar10.py
# time horovodrun -np 2 -H192.168.11.3:1,192.168.11.5:1 -p 12345 python cifar10.py
# time horovodrun -np 3 -H192.168.11.3:1,192.168.11.5:1,192.168.11.6:1 -p 12345 python cifar10.py
Secondary servers
$ sudo docker run -it --gpus all --net=host \
-v /mnt/nfs2/ssh:/root/.ssh \
-v /mnt/nfs/sample:/root/sample \
horovod/horovod:latest \
bash -c "/usr/sbin/sshd -p 12345; sleep infinity"
Execution results
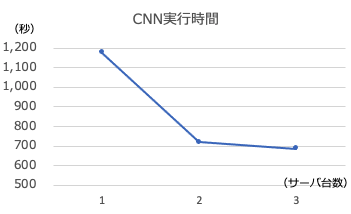
The REAL time measured by “time” is as follows.
| Number of Servers(units) | Execution Time(sec) |
|---|---|
| 1 | 1176 |
| 2 | 770 |
| 3 | 687 |
Summary
As shown above, the changes that need to be made to the original code can be roughly divided into additions and modifications, and it was found that the code can be used for distributed learning by adding/modifying just a few lines.
-
Additions
- Initialization: hvd.init()
- GPU and process binding: torch.cuda.set_device(hvd.local_rank())
-
Fixes
- In DataLoader, use Distributed sampler to split the dataset
- Wrap the optimizer with Distributed Optimizer
- Send parameters and optimizer stats from rank=0
I would like to learn more about modifying the code for use with Horovod in the future.