Introduction
In a recent post, I ran the ELYZA 7B model in a local environment using llama-cpp-python. In that post, I mentioned that “about the future” I would like to try to build a system that can chat like ChatGPT.
This time, I built a system that can chat like ChatGPT on a docker container, and I summarize its contents here.
Completed image
I built the system with the following configuration.
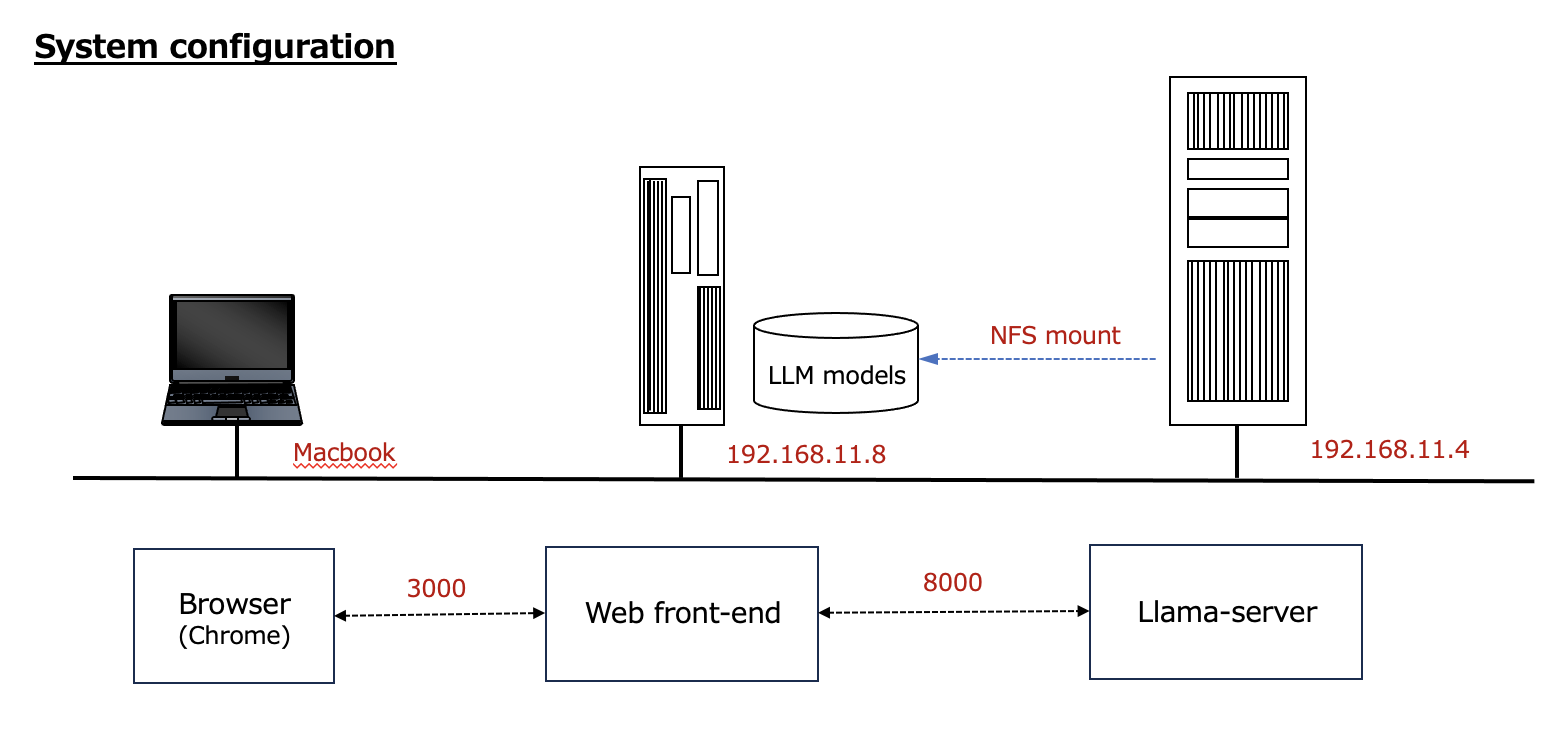
Sources
1.Handling multiple local LLMs with llama-cpp-python and Chatbot UI from ChatGPT-like WebUI It was useful for me to get an overall picture of the system.
2.Chatbot UI A github page for a tool that provides ChatGPT’s API in a Web UI. Currently updated to v2, v1 is in the legacy branch.
3.Chatbot UI (open source ChatGPT UI clone) hosted by Vercel A page that describes how to do the above in Japanese.
4.WEB Deployment of ELYZA Japanese LLaMA 2 13B The page I referred to most in this work.
5 WSL2 How to install the latest version of Node.js on Ubuntu The page I referred to for the procedure of upgrading node.
Llama-server
This is the right side of the “System Configuration” listed at the beginning of this post. LLMs such as “ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf” are stored on a central server disk and NFS mounted there.
Dockerfile
The “-model” option is written in CMD so that you can choose a model when starting the container, and “ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf” is used by default.
# Build an OpenAI compatible server
# Container with llama-cpp-python[server] installed
FROM nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04
# Set bash as the default shell
ENV SHELL=/bin/bash
# Build with some basic utilities
RUN apt-get update && apt-get install -y \
build-essential python3-pip apt-utils vim \
git git-lfs curl unzip wget
# alias python='python3'
RUN ln -s /usr/bin/python3 /usr/bin/python
# Install llama-cpp-python[server] with cuBLAS on
RUN CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 \
pip install llama-cpp-python[server] --force-reinstall --no-cache-dir
# Create the directory stored models
WORKDIR /models
# Launch llama_cpp server
ENTRYPOINT ["python3", "-m", "llama_cpp.server", "--chat_format", "llama-2", "--n_gpu_layers", "-1", "--host", "0.0.0.0"]
# set default model
CMD ["--model", "ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf"]
Build a container
In the directory with the above Dockerfile, build the container as follows
$ sudo docker build -t llama-server .
Start the container
The created container is started as follows. As you can see below, the LLM is stored in /mnt/nfs2/models. The entity is located on the NFS mount.
export MODEL_DIR=/mnt/nfs2/models
export CUDA_VISIBLE_DEVICES=0
sudo docker run --rm --gpus all -v ${MODEL_DIR}:/models -p 8000:8000 llama-server:latest
Web Front End
Actually, I had a bit of trouble with this part.
At first, after installing npm and brew, I was planning to build a web frontend (Chatbot-ui) according to source 2. Since I was thinking of making it a Docker container, I thought installing brew would be a bit difficult with my know-how.
So I decided to build it by cloning the legacy branch according to source 4. There is a Dockerfile there, so I thought it would be easy to build.
I cloned the legacy branch as follows
$ git clone -b legacy https://github.com/mckaywrigley/chatbot-ui.git
$ cd chatbot-ui
built a container
The container was built from the Dockerfile in the chatbot-ui directory as follows.
$ sudo docker build -t chatgpt-ui ./
launch a contaier
$ sudo docker run --rm -e OPENAI_API_KEY=fake_key -p 3000:3000 chatgpt-ui:latest
It does not connect to Llama-sever. Perhaps it is trying to connect to the default “http://localhost:8000”. I specified “-e OPENAI_API_HOST=“http://192.168.11.4:8000"” when launching the container, but it does not work.
I gave up containerizing the web front-end part and started it from npm following the procedure in source 4. I will explain how to do it.
Build a web front end on a physical environment
Install the npm needed to build the front end on the physical environment.
$ sudo apt install npm
Then, in accordance with Source 4, perform the following
$ npm i
$ npm audit fix --force
$ cp .env.local.example .env.local
Add the following to .env.local
# Chatbot UI
OPENAI_API_HOST="http://192.168.11.4:8000"
OPENAI_API_KEY=fake_key
DEFAULT_SYSTEM_PROMPT="あなたは誠実で優秀な日本人のアシスタントです。"
Webフロントエンドを起動
$ npm run dev
The following error was found.
/home/kenji/tmp/chatbot-ui/node_modules/next/dist/lib/picocolors.js:134
const { env, stdout } = ((_globalThis = globalThis) == null ? void 0 : _globalThis.process) ?? {};
^
SyntaxError: Unexpected token '?'
Since it is usually hard to imagine an error in the provided source, I thought that the node (node.js) version might be out of date, so I performed the following steps.
error response - node update
I updated node to the latest version as follows according to source 5.
$ node -v
v12.22.9
$ sudo npm install -g n
$ sudo n lts
installing : node-v20.12.2
(abbreviation)
old : /usr/bin/node
new : /usr/local/bin/node
(abbreviation)
$ node -v
v12.22.9
Here, reboot. After the reboot, the system is updated to the latest version as follows.
$ node -v
v20.12.2
After updating node, launch web front end
$ npm run dev
Connecting from a browser
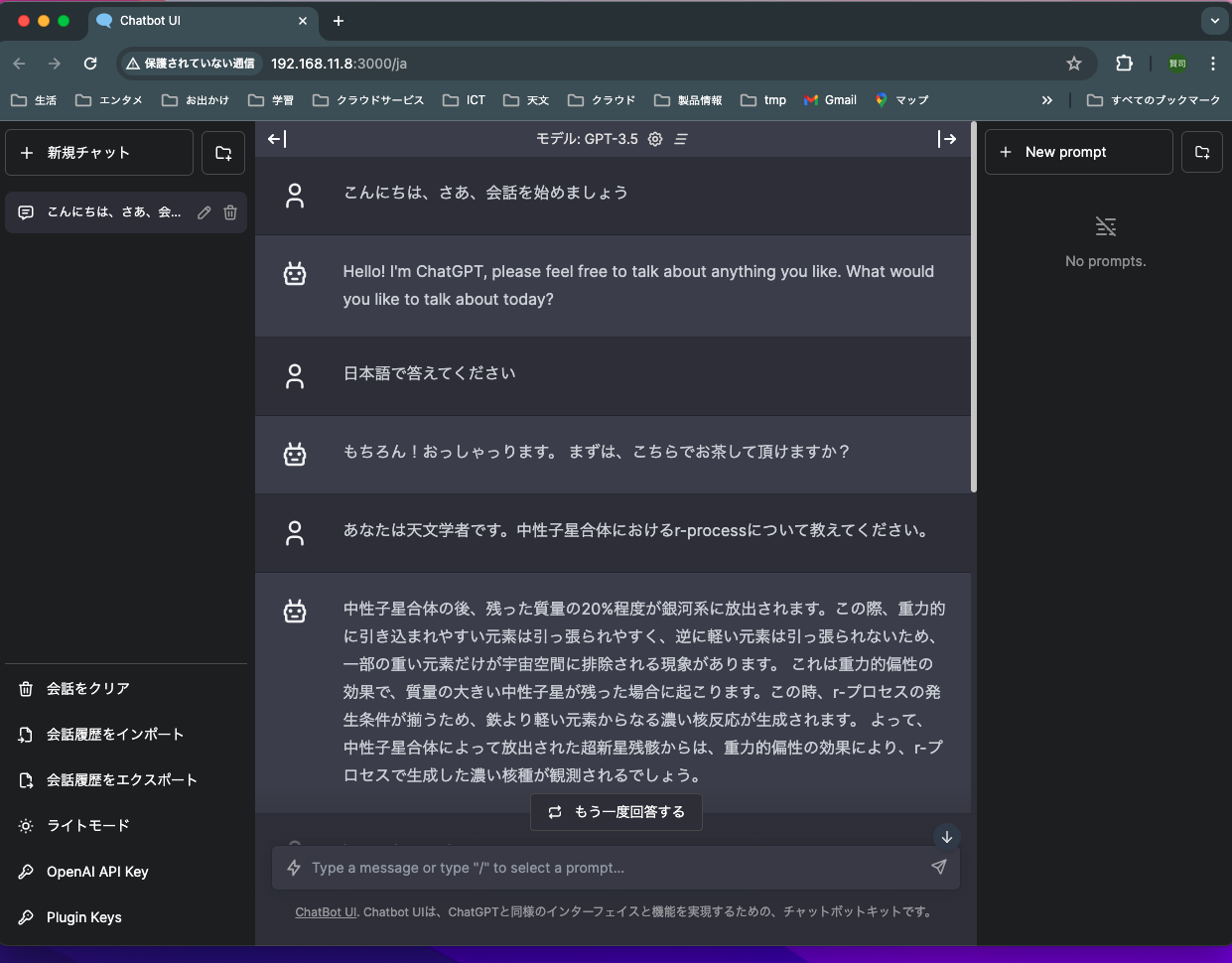
I connected to the web front end with “http://192.168.11.8:3000” using Chrome on my MacBookPro, and was able to connect to LLM and have a chat.
Start of chat. The first chat, which was in Japanese, made no sense.
I threw the question I always ask LLM, “Explanation about r-process”.
I asked in English.
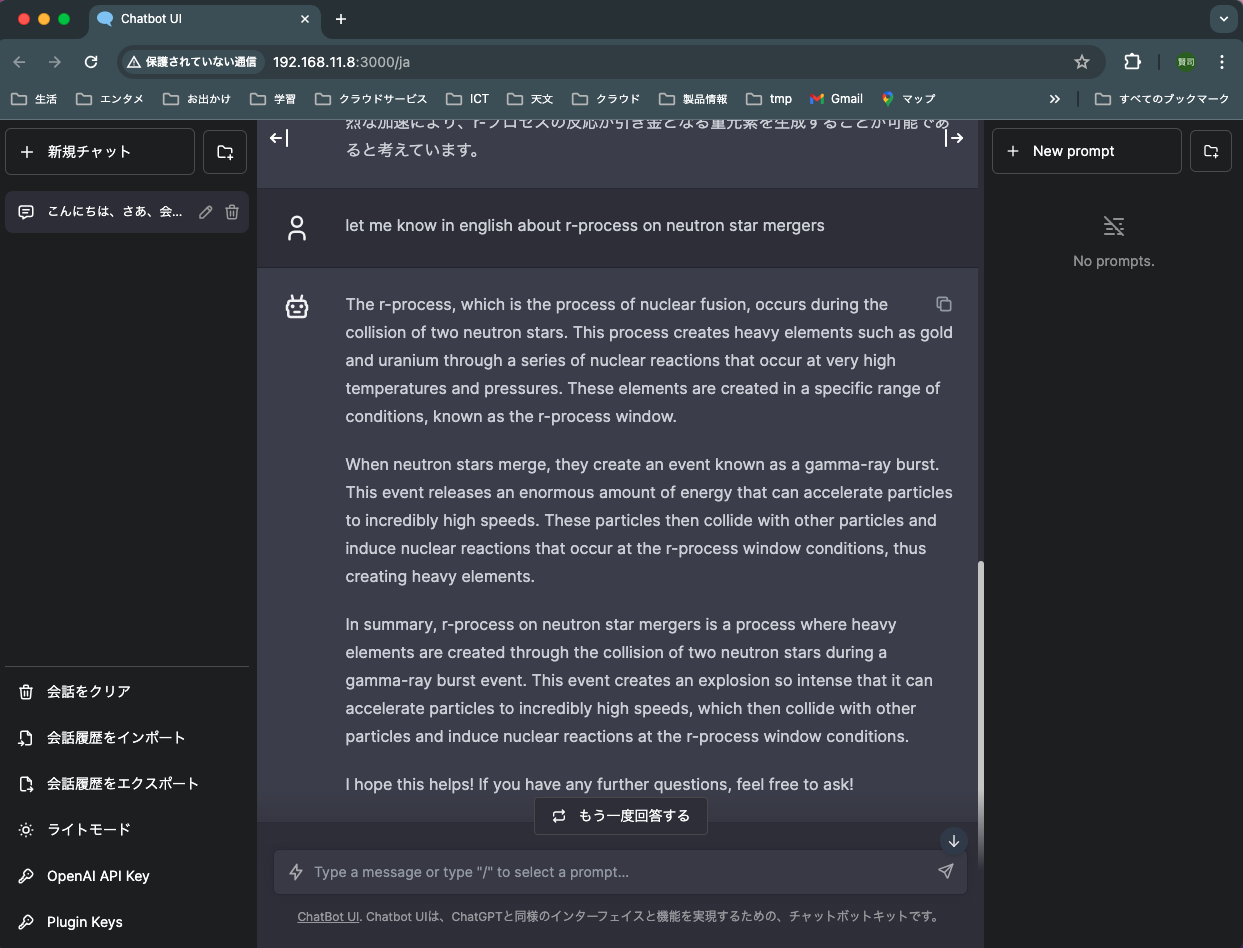
More detailed and accurate answer in English.
Summary
Although there were a few troubles, I was able to make a ChatGPT-like system in a local environment.
In the future, I would like to try the following
- Containerization of the web front end and v2 support
- Switching LLM
- Linking to the RAG