Introduction
A while ago in this post, I described how I installed neo4j in a local environment (as a docker container) in order to use the knowledge graph.
In this post, I would like to summarize the contents of the simple knowledge graph that I built and used as a RAG, referring to an article on the Internet. I titled this post as first steps because I did exactly what the article on the internet said.
Sources
- Implementing RAG with Knowledge Graph in LangChain Part 1 The content of this post was run directly from the code in this article (hereinafter referred to as the “source code”). The content is intended to help the reader understand the flow of implementing RAG for the Knowledge Graph.
- Enhancing the Accuracy of RAG Applications With Knowledge Graphs Neo4J Developer Blog. Sources 1. appears to be based on this page and the github that is pointed to on this page.
About LLM
The source code was tested with 6 LLMs. The execution results are as follows.
| LLM | Execution Result |
|---|---|
| PLaMo β | BadRequestError: Error code: 400 - {‘message’: ‘invalid field: parallel_tool_calls’} |
| Llama-3-ELYZA-JP-8B-q4_k_m.gguf | ImportError: Could not import json_repair python package. Please install it with pip install json-repair.Added json-repair and ran it, but got the following error. Looks like the graph was not created?Received notification from DBMS server: {severity: WARNING} {code: Neo.ClientNotification.Statement.UnknownRelationshipTypeWarning} {category: UNRECOGNIZED} {title: The provided relationship type is not in the database.} {description: One of the relationship types in your query is not available in the database, make sure you didn’t misspell it or that the label is available when you run this statement in your application (the missing relationship type is: MENTIONS)} {position: line: 1, column: 15, offset: 14} for query: ‘MATCH (s)-[r:!MENTIONS]->(t) RETURN s,r,t LIMIT 50’ |
| llama-3-youko-8b-instruct.Q6_K.gguf | TypeError: string indices must be integers |
| gpt-4o | Correctly executed. The above two LLMs did not seem to execute correctly, so I used the same LLMs used in the “soucrce code”. There was another article on this article that had the same problem with the LLMs. |
| gpt-4o-mini | Correctly executed.To reduce API usage fees, I started using this one. |
| Mistral-7B-Instruct-v0.3-Q6_K.gguf | TypeError: list indices must be integers or slices, not str |
According to sources 2., the supported LLMs are OpenAI and Mistral, so I tried “Mistral-7B-Instruct-v0.3-Q6_K.gguf” but it failed as shown in the table above. Does it have to be an API version like OpenAI?
Procedure
Dockerfile
The following is an excerpt from jupyterlab’s Dockerfile with the necessary packages added to run the “source code”. The rest of the Dockerfile is identical to the Dockerfile in this article.
RUN pip install --upgrade pip setuptools \
&& pip install torch==2.2.2 torchvision==0.17.2 torchaudio==2.2.2 \
--index-url https://download.pytorch.org/whl/cu121 \
&& pip install torch torchvision torchaudio \
&& pip install jupyterlab matplotlib pandas scikit-learn ipywidgets \
&& pip install transformers accelerate sentencepiece einops \
&& pip install langchain bitsandbytes protobuf \
&& pip install auto-gptq optimum \
&& pip install pypdf tiktoken sentence_transformers faiss-gpu trafilatura \
&& pip install langchain-community langchain_openai wikipedia \
&& pip install langchain-huggingface unstructured html2text rank-bm25 janome \
&& pip install langchain-chroma sudachipy sudachidict_full \
&& pip install mysql-connector-python \
&& pip install langchain-experimental neo4j pandas \
&& pip install json-repair
The additional part to execute the “source code” is the second line from the end, “pip install langchain-experimental neo4j pandas”. The last “pip install json-repair” was added because using the Llama-3-ELYZA-JP-8B-q4_k_m.gguf model resulted in an error, as described in “Execution Results” in “About LLM”.
Create Graph
The “source code” was executed as is. Only the code added/modified for my environment is shown below.
# neo4j用の環境変数を設定
import os
os.environ['NEO4J_URI'] = 'bolt://192.168.11.8:7687'
os.environ['NEO4J_USERNAME'] = 'neo4j'
os.environ['NEO4J_PASSWORD'] = 'password'
NEO4J_URI is the IP address and port of the server running the container installed in this article.
For more information, see this Docs page. Actually, this is where I got myself into trouble.
NEO4J_USERNAME/PASSWORD is the ID and password specified in NEO4J_AUTH in docker-compose.yml in the same article.
# OpenAIのAPIキーを設定する
import os
os.environ['OPENAI_API_KEY'] = 'xxxx'
The “xxxx” part is the API key obtained.
The following is a screen capture of the obtained graph when it was checked by connecting from a browser.
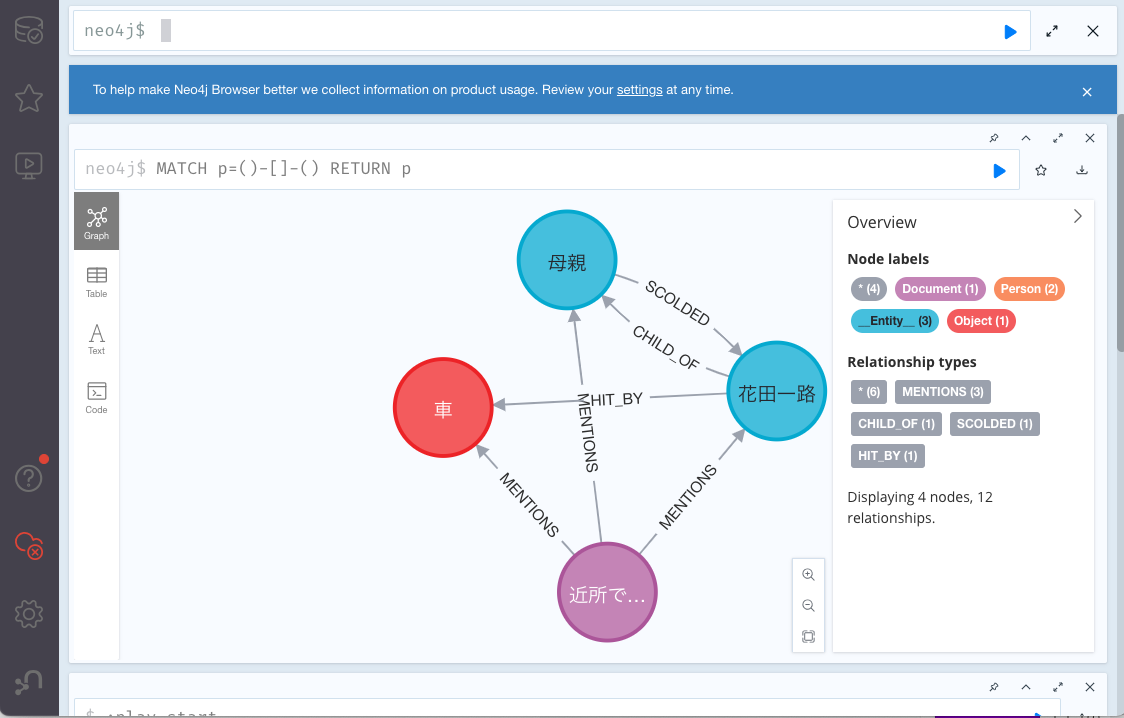
Create a Vector Store index
Further, create an index in Neo4jVector according to the “source code”. As with the article, check for additions.
retriever from Graph and from Vector Store
The “2. LLM execution in RAG” part of the “source code” was also executed as is.
The partial code of Chain that I executed is as follows.
# Chainを実行
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
template = """Answer the question based only on the following context:
{context}
Question: {question}
Use natural language and be concise.
Answer:"""
prompt = ChatPromptTemplate.from_template(template)
chain = (
RunnableParallel(
{
"context": retriever,
"question": RunnablePassthrough(),
}
)
| prompt
| ChatOpenAI(temperature=0, model_name="gpt-4o")
| StrOutputParser()
)
chain.invoke("花田はどんな人間?")
The results of the execution are as follows:
Search query: 花田はどんな人間?
'花田一路は近所でも有名な腕白小僧です。'
About the future
I have now been able to try the RAG system using Knowledge Graphs in my own environment.
In the future, after trying Part 2 of the source article, I would like to try Graph RAG using my own data.
Furthermore, I would like to do some more research to see if I can use LLMs other than gpt-*.