Introduction
Yesterday in this post I summarized launching ollama in a docker container and using LLMs from JupyterLab. In this post, I summarize launching Open WebUI in a container and using it as a front end to connect from a browser at hand to use ollama’s LLMs.
Completed image
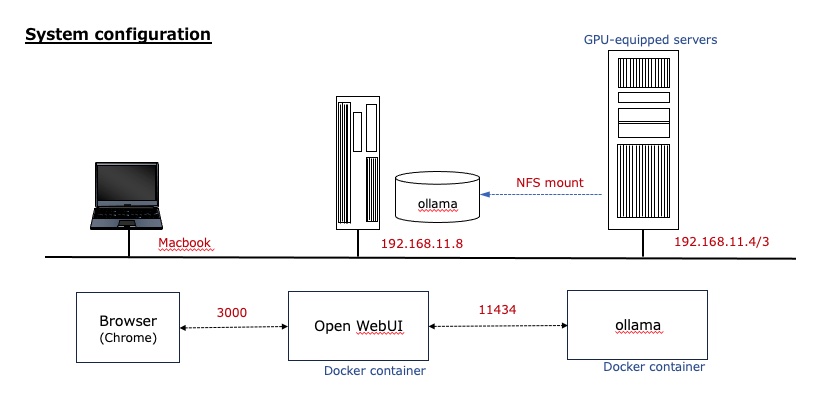
The system was built with the following configuration; see also yesterday’s post for NFS mounts.
Information sources
- open-webui/open-webui - Open-webUI’s official github page.
- Open WebUI - how to start open-webui with Docker.
- Using Local LLM - Explains how Ollama and Open WebUI work together - explains how to install ollama and open-webui with docker. The article explains how to do this. ollama and open-webui are started together (on the same host) in docker-compose.yml, which is different from what I’m trying to do this time.
Launch Open WebUI
Create docker-compose.yml
Create a configuration file (docker-compose.yml) to launch Open WebUI, referring to source 2.
services:
open-webui:
image: ghcr.io/open-webui/open-webui:cuda
container_name: open-webui
environment:
- OLLAMA_BASE_URL=http://192.168.11.4:11434
volumes:
- ./data:/app/backend/data
ports:
- 3000:8080
restart: always
OLLAMA_BASE_URL specifies the IP address and port number of the host on which ollama is running (although it is actually running in a container within that host). This is the most important point.
I use open-webui:cuda for the image, but even open-webui:main seems to use GPU in the ollama container. (from memory usage and GPU usage on nvidia-smi)
Start Open WebUI
I started open-webui with docker compose command and verified the startup with docker ps command.
$ ls -l
合計 20
drwxrwxr-x 5 kenji kenji 4096 11月 23 10:44 data
-rw-rw-r-- 1 kenji kenji 264 11月 23 10:41 docker-compose.yml
-rw-rw-r-- 1 kenji kenji 264 11月 23 10:25 gamenyde_docker-compose-cuda.yml
-rw-rw-r-- 1 kenji kenji 264 11月 22 14:26 jupiter_docker-compose.yml
$ sudo docker compose up -d
$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5e3b265ccced ghcr.io/open-webui/open-webui:cuda "bash start.sh" 4 minutes ago Up 4 minutes (healthy) 0.0.0.0:3000->8080/tcp, [::]:3000->8080/tcp open-webui
Start from a browser
In a browser, type “http://192.168.11.8:3000/” to display the Open WebUI startup screen. After entering your name, e-mail address, and password, the screen will accept questions.

You can see that the LLM currently in use is “schroneko/gemma-2-2b-jpn-it”.
If you click on the “v” at the top, the LLM pulled by ollama will be displayed as follows, and you can change the LLM.

The following is a list of models that have been pulled by entering the ollama container.
$ sudo docker exec -it ollama /bin/bash
[sudo] kenji のパスワード:
# ollama list
NAME ID SIZE MODIFIED
neoai-8b-chat:latest ad598b8bec6a 8.5 GB 18 hours ago
llama3.2:latest a80c4f17acd5 2.0 GB 19 hours ago
hf.co/elyza/Llama-3-ELYZA-JP-8B-GGUF:latest 4d9f57e24956 4.9 GB 20 hours ago
schroneko/gemma-2-2b-jpn-it:latest fcfc848fe62a 2.8 GB 21 hours ago
# ollama ps
NAME ID SIZE PROCESSOR UNTIL
schroneko/gemma-2-2b-jpn-it:latest fcfc848fe62a 4.8 GB 100% GPU 4 minutes from now
Summary
In my environment, the behavior of character input on a browser (Chrome) connected to Open WebUI is slightly strange. A string of characters entered up to the “Return” input of the Japanese input (Kana-Kanji conversion) confirmation is queried to ollama and the result is returned. The input field still contains the confirmed character string entered before “Return”.
Also, when using “hf.co/elyza/Llama-3-ELYZA-JP-8B-GGUF”, the answer from LLM is sometimes repeated many times.
Six months ago in this post, I summarized the details of a system I built using Chatbot UI. At that time, I had a hard time containerizing Llama-server running on a GPU machine, but this time, I was able to build a similar system with relative ease.