はじめに
深層学習day2の「Section2:学習率最適化手法」の実装演習を以下にまとめる。
実装演習
「2_4_optimize.ipynb」のコードを参照した。
試したのは、確率的勾配降下法(SGD)、モメンタム、AdaGrad、RMSProp、Adamについて、各々で「use_batchnorm」をTrue/False(即ちバッチ正規化をOn/Off)の 2通りを試した。
コードについては、今回は掲載しない。結果を正答率のグラフのみを示す。
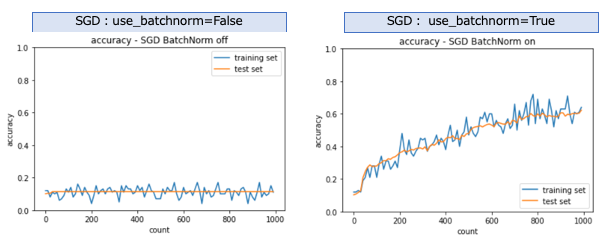
SGD
バッチ正規化が無効の場合は学習は全く進まなかったが、バッチ正規化を有効にすると学習が進む事がわかる。
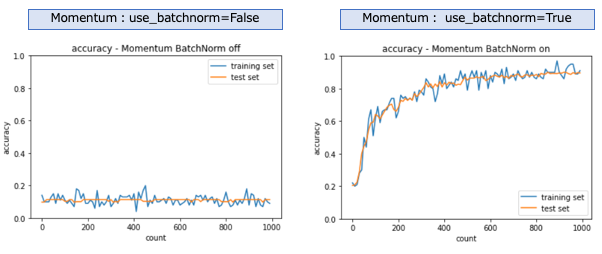
モメンタム
SGDと同じくバッチ正規化が無効の場合は学習は進まなかった。バッチ正規化を有効にすると学習が進む。SGDよりも良い結果を示している。
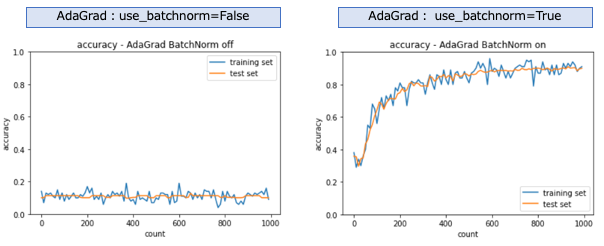
AdaGrad
SGD、モメンタムと同じくバッチ正規化が無効の場合は学習は進まなかった。バッチ正規化を有効にすると学習が進む。モメンタムより少し学習が早く進んでいるように見える。
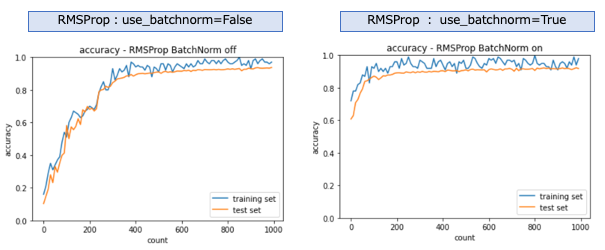
RMSProp
バッチ正規化を有効にせずとも学習は進んでいる事がわかる。更にバッチ正規化すると、非常に短期間で学習が進んでいることが分かる。
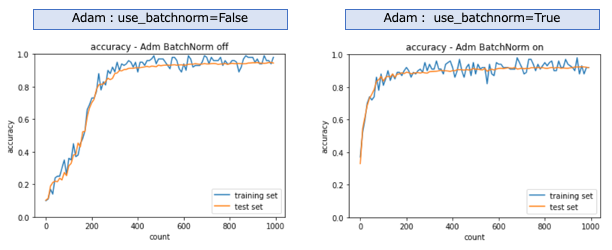
Adam
RSMPropと同じく、バッチ正規化せずとも学習が進む。バッチ正規化すると、急速に学習が進む事がわかる。