はじめに
深層学習day2の「Section5:最新のCNN」の実装演習を以下にまとめる。
実装演習
「2_8_deep_convolution_net.ipynb」を試した。
このネットワークは、畳み込み層が6層(Conv1-6)、プーリング層が3層(Conv2、Conv4、Conv6の次の層に)、全結合層が 2層(ドロップアウト付き)の構成である。
# 自分の環境で、ダウンロードした共通関数の格納フォルダのパス
import sys
sys.path.append('DNN_code_colab_lesson_1_2')
sys.path.append('DNN_code_colab_lesson_1_2/lesson_2')
import pickle
import numpy as np
from collections import OrderedDict
from common import layers
from data.mnist import load_mnist
import matplotlib.pyplot as plt
from common import optimizer
class DeepConvNet:
'''
認識率99%以上の高精度なConvNet
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
conv - relu - conv- relu - pool -
affine - relu - dropout - affine - dropout - softmax
'''
def __init__(self, input_dim=(1, 28, 28),
conv_param_1 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_2 = {'filter_num':16, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_3 = {'filter_num':32, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_4 = {'filter_num':32, 'filter_size':3, 'pad':2, 'stride':1},
conv_param_5 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
conv_param_6 = {'filter_num':64, 'filter_size':3, 'pad':1, 'stride':1},
hidden_size=50, output_size=10):
# 重みの初期化===========
# 各層のニューロンひとつあたりが、前層のニューロンといくつのつながりがあるか
pre_node_nums = np.array([1*3*3, 16*3*3, 16*3*3, 32*3*3, 32*3*3, 64*3*3, 64*4*4, hidden_size])
wight_init_scales = np.sqrt(2.0 / pre_node_nums) # Heの初期値
self.params = {}
pre_channel_num = input_dim[0]
for idx, conv_param in enumerate([conv_param_1, conv_param_2, conv_param_3, conv_param_4, conv_param_5, conv_param_6]):
self.params['W' + str(idx+1)] = wight_init_scales[idx] * np.random.randn(conv_param['filter_num'], pre_channel_num, conv_param['filter_size'], conv_param['filter_size'])
self.params['b' + str(idx+1)] = np.zeros(conv_param['filter_num'])
pre_channel_num = conv_param['filter_num']
self.params['W7'] = wight_init_scales[6] * np.random.randn(pre_node_nums[6], hidden_size)
print(self.params['W7'].shape)
self.params['b7'] = np.zeros(hidden_size)
self.params['W8'] = wight_init_scales[7] * np.random.randn(pre_node_nums[7], output_size)
self.params['b8'] = np.zeros(output_size)
# レイヤの生成===========
self.layers = []
self.layers.append(layers.Convolution(self.params['W1'], self.params['b1'],
conv_param_1['stride'], conv_param_1['pad']))
self.layers.append(layers.Relu())
self.layers.append(layers.Convolution(self.params['W2'], self.params['b2'],
conv_param_2['stride'], conv_param_2['pad']))
self.layers.append(layers.Relu())
self.layers.append(layers.Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(layers.Convolution(self.params['W3'], self.params['b3'],
conv_param_3['stride'], conv_param_3['pad']))
self.layers.append(layers.Relu())
self.layers.append(layers.Convolution(self.params['W4'], self.params['b4'],
conv_param_4['stride'], conv_param_4['pad']))
self.layers.append(layers.Relu())
self.layers.append(layers.Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(layers.Convolution(self.params['W5'], self.params['b5'],
conv_param_5['stride'], conv_param_5['pad']))
self.layers.append(layers.Relu())
self.layers.append(layers.Convolution(self.params['W6'], self.params['b6'],
conv_param_6['stride'], conv_param_6['pad']))
self.layers.append(layers.Relu())
self.layers.append(layers.Pooling(pool_h=2, pool_w=2, stride=2))
self.layers.append(layers.Affine(self.params['W7'], self.params['b7']))
self.layers.append(layers.Relu())
self.layers.append(layers.Dropout(0.5))
self.layers.append(layers.Affine(self.params['W8'], self.params['b8']))
self.layers.append(layers.Dropout(0.5))
self.last_layer = layers.SoftmaxWithLoss()
def predict(self, x, train_flg=False):
for layer in self.layers:
if isinstance(layer, layers.Dropout):
x = layer.forward(x, train_flg)
else:
x = layer.forward(x)
return x
def loss(self, x, d):
y = self.predict(x, train_flg=True)
return self.last_layer.forward(y, d)
def accuracy(self, x, d, batch_size=100):
if d.ndim != 1 : d = np.argmax(d, axis=1)
acc = 0.0
for i in range(int(x.shape[0] / batch_size)):
tx = x[i*batch_size:(i+1)*batch_size]
td = d[i*batch_size:(i+1)*batch_size]
y = self.predict(tx, train_flg=False)
y = np.argmax(y, axis=1)
acc += np.sum(y == td)
return acc / x.shape[0]
def gradient(self, x, d):
# forward
self.loss(x, d)
# backward
dout = 1
dout = self.last_layer.backward(dout)
tmp_layers = self.layers.copy()
tmp_layers.reverse()
for layer in tmp_layers:
dout = layer.backward(dout)
# 設定
grads = {}
for i, layer_idx in enumerate((0, 2, 5, 7, 10, 12, 15, 18)):
grads['W' + str(i+1)] = self.layers[layer_idx].dW
grads['b' + str(i+1)] = self.layers[layer_idx].db
return grads
(x_train, d_train), (x_test, d_test) = load_mnist(flatten=False)
# 処理に時間のかかる場合はデータを削減
x_train, d_train = x_train[:5000], d_train[:5000]
x_test, d_test = x_test[:1000], d_test[:1000]
print("データ読み込み完了")
network = DeepConvNet()
optimizer = optimizer.Adam()
iters_num = 1000
train_size = x_train.shape[0]
batch_size = 100
train_loss_list = []
accuracies_train = []
accuracies_test = []
plot_interval=10
for i in range(iters_num):
batch_mask = np.random.choice(train_size, batch_size)
x_batch = x_train[batch_mask]
d_batch = d_train[batch_mask]
grad = network.gradient(x_batch, d_batch)
optimizer.update(network.params, grad)
loss = network.loss(x_batch, d_batch)
train_loss_list.append(loss)
if (i+1) % plot_interval == 0:
accr_train = network.accuracy(x_train, d_train)
accr_test = network.accuracy(x_test, d_test)
accuracies_train.append(accr_train)
accuracies_test.append(accr_test)
print('Generation: ' + str(i+1) + '. 正答率(トレーニング) = ' + str(accr_train))
print(' : ' + str(i+1) + '. 正答率(テスト) = ' + str(accr_test))
lists = range(0, iters_num, plot_interval)
plt.plot(lists, accuracies_train, label="training set")
plt.plot(lists, accuracies_test, label="test set")
plt.legend(loc="lower right")
plt.title("accuracy")
plt.xlabel("count")
plt.ylabel("accuracy")
plt.ylim(0, 1.0)
# グラフの表示
plt.show()
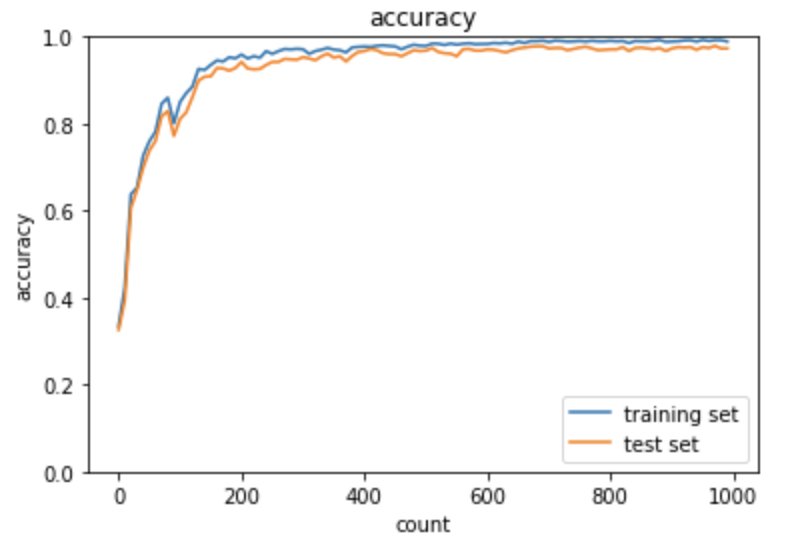
正解率が97%と非常に精度が高いことが分かる。
深層学習day1およびday2の実装を通じての所感
深層学習day2の「Section3:過学習について」までの実装演習は、比較的短時間で実行が完了したが、「Section4:畳み込みニューラルネットワーク」および「Section5:最新のCNN」の実装演習では、それまでに比較して比較的長時間(約1時間程度)かかった。
高速化のための一つの方法としてGPUを利用することが考えられる。実は自分のローカル環境でもGPUが利用できる。これまでの実装は、numpyを使っての実装なので、コードをGPU化するには、cupyを使いそれに合わせてコードを変更する必要がある。それは、単にimport文のnumpyをcupyに変えるだけでなく、コード中の変数をCPU側とデバイス(GPU)側にうまく分離する必要がある。中々一筋縄ではいかない。
PytorchやTensoFlowというフレームワークを使うメリットは、その点(コードのGPU化との観点)においてもあると考える。
例えば、Pytorchの場合、次のような判定を入れる。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
a = a.to(device)
とすれば、GPUが使える環境では、変数aはGPU側で処理されるように成る。
Pytorchで定義したネットワークモデルを上記例のようにGPU側で使えるように考慮して記述しておけば、コードを変更することなくGPUを使用できる。