はじめに
前回のこの記事に引き続き、JDLA E資格のシラバスの範囲で、「深層学習 day3およびday4」についてまとめたものである。今回の範囲は、RNN、LSTM、Seq2seq、強化学習、Transformerなど深層学習を言語処理などの応用分野への適用につながる興味深い領域である。
この記事がこのラビットチャレンジのレポートのシリーズ最終回である。
参考文献
以下は、自分が学習する際に手元において参考にしている書籍である。
- ゼロから作るDeep Learning② 斎藤康毅著 オライリー・ジャパン
→ 前回のレポートで参考文献にあげた「ゼロから作るDeep Learning」の続編で、自然言語処理に関するもの。前作と同じように、実際にコードを動かしながら学べる。 - 深層学習 Ian Goodfellow, Yoshua Bengio, AronCourville 著 岩澤有祐、鈴木雅大、中山浩太郎、松尾豊 監訳 ドワンゴ
→ Deep Learningの教科書的書籍。上記書籍で若干説明不足の数学的背景が追える。前回も言ったが、自分は部分的にしか参照できていない。 - 深層強化学習入門 伊藤多一、今津義充、須藤広大、仁ノ平将人、川崎悠介、酒井裕企、魏崇哲 著 翔泳社
→ 深層学習の基礎(CNN、RNN、LSTM)、強化学習の基礎(Q学習、方策勾配法、Actor-Critic法)、および具体的な応用例3つの実装・解説。こちらも手を動かしながら学べる。 - 最強囲碁AI アルファ碁解体新書 大槻知史 著 翔泳社
→ アルファ碁に関する論文を噛み砕き、アルファ碁で利用されている深層学習、強化学習、モンテカルロ木探索の仕組みを解説した書籍。
深層学習day3
Section1:再帰型ニューラルネットワークの概念
概要
RNNと時系列データ
再帰型ニューラルネットワーク(Recurrent Neural Network; RNN)は時系列データに対応可能なニューラルネットワークである。
時系列データとは、時間的順序を追って一定間隔ごとに観測され、しかも相互に統計的依存関係が認められるようなdーたの系列をいう。具体的には、次のようなデータである。
- 音声データ
- テキストデータ
RNNの特徴
RNNの特徴は、時系列モデルを扱うには、初期の状態と過去の時間t-1の状態を保持し、そこから次の時間でのtを再帰的に求める再帰構造を持っていることである。
BPTT
Backpropagation Trough Time(BPTT)は、RNNにおいてのパラメータ調整方法の一種(誤差逆伝播法の一種)である。
確認テスト
RNNの3つの重みについて
RNNのネットワークには大きく分けて3つの重みがある、以下の 2つ以外の重みについて説明する。
- 入力から現在の中間層を定義するのに掛けられる重み:$W_{(in)}$
- 中間層から出力を定義する際に掛けられる重み:$W_{(out)}$
→ 前の中間層から現在の中間層に掛けられる重み: $W$である。
連鎖律を用いてdz/dxを求める
$$ \begin{align} z &= t^2 \\ t &= x + y \end{align} $$
上記の時に、連鎖律を用いて、$\frac{dz}{dx}$を求める。 $$ \frac{dz}{dx} = \frac{dz}{dt}\frac{dt}{dx} = 2t \times 1=2(x+y) $$
RNN出力式
下図の$y_1$を$S_0,S_1,W_{in},W,W_{out}$を用いて表す。
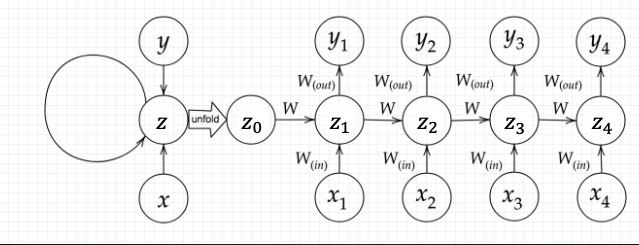
以下の通りである。但し、$g(x)$はシグモイド関数である。 $$ \begin{align} S_1 &= W_{in} x_1 + W S_0 + b \\ y_1 &= g(W_{out} S_1+c) \end{align} $$
演習チャレンジ
再帰的に文全体の表現ベクトルを得るプログラム
空欄を埋めたコードを以下に示す。
def traverse(node):
if not isinstance(node, dict):
v = node
else:
left = travearse(node['left'])
right = traverse(node['right'])
v = _activation(W.dot(np.concatenate([left, right])))
return v
隣接単語(表現ベクトル)から表現ベクトルを作るという処理は、隣接している表現 left と right を合わせたものを特徴量としてそこに重みを掛けることで実現する。したがって、W.dot(np.concatenate([left, right]))である。
実装演習
RNNの実装演習の結果、考察などについては、こちらの記事に掲載。
Section2:LSTM
概要
LSTMとは
RNNの課題・解決策
時間列を遡れば遡るほど、勾配が損失していく。そのため、長い時系列の学習が困難となる。構造自体を変えて勾配損失を解決したものがLSTMである。
勾配損失問題とは
誤差逆伝播法が下位層に進んでいくに連れて、勾配がどんどん緩やかになっていく。そのため、勾配降下法による更新では、下位層のパラメータがほとんど変わら図、訓練は最適値に収束しなくなる。
勾配爆発
一方、勾配爆発とは、勾配が層を逆伝播するごとに指数関数的に大きくなっていくことを言う。勾配爆発を防ぐために、勾配クリッピングを行い、しきい値を超えたら勾配のノルムをしきい値に正規化する、ということもある。
LSTM全体図
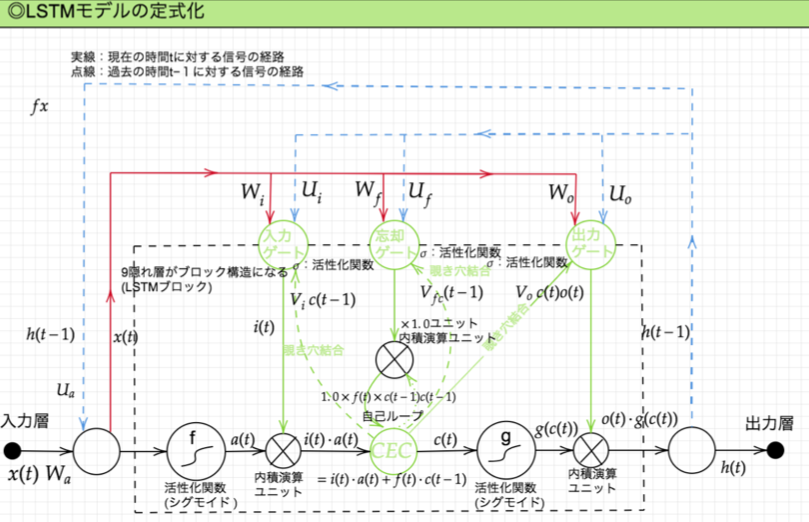
CEC(Constant Error Carousel)
LSTM全体図において、中間層にあるCEC(constant error carousel)が重要。RNNの問題点は、中間層に記憶を溜め込むわけだが、そのときに中間層が増えれば増えるほどに学習の過程で勾配が小さくなっていき勾配消失が起きてしまう。CECでは記憶することだけをもたせて、学習は分離する。そうすることで勾配がどんどん小さくなることを防ぐ。
CECの課題は、入力データについて、時間依存度に関係なく重みが一律である。つまり、ニューラルネットワークの学習特性がないことである。
入力ゲートと出力ゲート
入力ゲートは、CECに「どのような記憶のさせ方するか」を伝える。前のユニットの入力から受け取る割合を調整する。
出力ゲートは、CECに「どのような記憶の取り出し方をするか」を伝える。前のユニットの出力をどの程度受け取るかを調整する。
入力ゲート、出力ゲートを追加することで、それぞれのゲートへの入力値の重みを、重み行列$\boldsymbol{W},\boldsymbol{U}$で可変可能とする。これにより、前述したCECの課題を解決できる。
忘却ゲート
CECは、過去の情報が全て保存されており、過去の情報が要らなくなった場合、削除することはできず、保存され続ける。そのため、過去の情報が要らなくなった(インプットが大きな変化をした)場合に、メモリセルで記憶した内容を忘れることを学習する。
覗き穴結合
除き台結合とは、CEC自身の値に、重み行列を介して伝播可能にした構造を言う。実際にはあまり大きな効果の改善は見られないとのこと。
確認テスト
シグモイド関数を微分した時、入力値がゼロの時の最大値は?
シグモイド関数、およびその微分は、次の通り。 $$ \begin{align} f(x) &= \frac{1}{1+\exp(-x)} \\ f’(x) &= (1-f(x))f(x) \end{align} $$ したがって、$f’(0)=(1-f(0))f(0)=0.25$となる。($f(0)=0.5$であることより)
特定の言葉が予測に影響を及ぼさない場合に作用するゲートは?
以下の文章にLSTMに入力し空欄に当てはまる単語を予測したいとする。文中の「とても」という言葉は空欄の予測において無くなっても影響を及ぼさないと考えられるか。このような場合、どのゲートが作用すると考えられるか。 「映画面白かったね。ところで、とてもお腹が空いたから何か__。」
→ 忘却ゲート
実装演習
本節では、実装演習は無し。
Section3:GRU
概要
GRUとは
従来のLSTMでは、パラメータが多数存在していたため、計算負荷が大きかった。しかし、GRUでは、そのパラメータを大幅に削減し、精度は同等またはそれ以上が望めるようになった構造である。
計算負荷が低いことがメリットである。
GRUの全体像
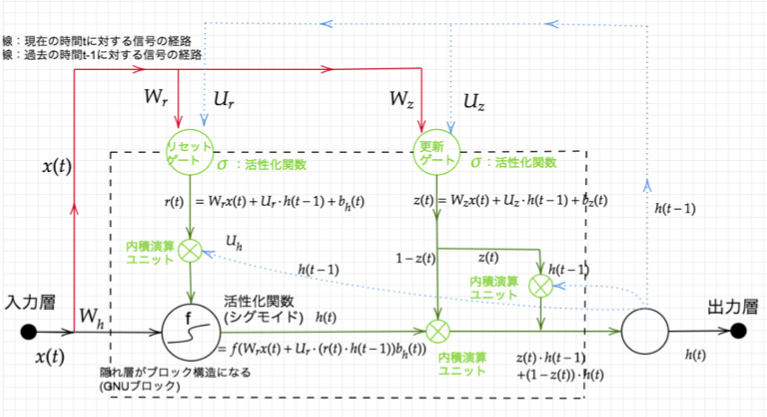
確認テスト
LSTMとCECが抱える課題は?
LSTMにおいては、入力ゲート、出力ゲート、忘却ゲート、CEC、と4つの部品から構成され、パラメータが多く、計算量が多い。
CECは、勾配が1で学習能力がない。
LSTMとGRUの違いは?
LSTMは、入力ゲート、出力ゲート、忘却ゲート+CECで構成される。一方、GRUは更新ゲート、リセットゲートの2つで構成される。従って、パラメータの数はLSTMよりGRUのほうが少ないので、計算量が少なくて良い。
実装演習
GRUの実装演習の結果、考察などについては、こちらの記事に記載。
Section4:双方向RNN
概要
双方向RNNとは、過去の情報だけでなく、未来の情報を加味することで、精度を向上させるためのモデルである。
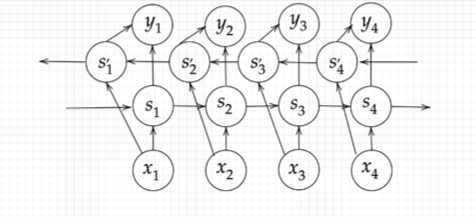
文章の推敲や機械翻訳などで使われている。
演習チャレンジ
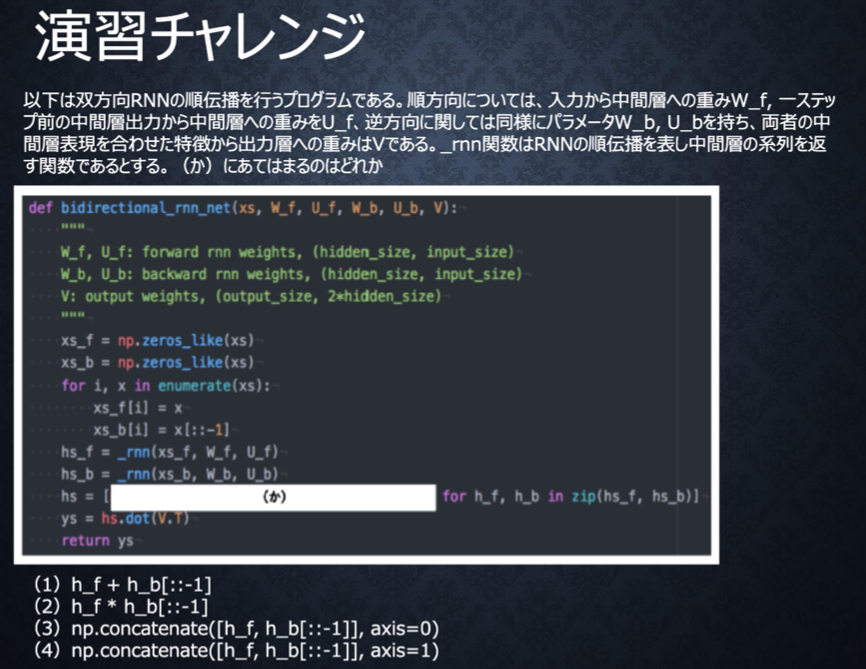
双方向RNNでは、順方向と逆方向に伝播した時の中間層表現をあわせたものが特徴量となるので、正解は(4)であり、該当行は以下の通り。
hs = [np.concatenate([h_f, h_b[::-1]], axis=1) for h_f, h_b in zip(hs_f, hs_b)]
実装演習
本節では、実装演習は無し。
Section5:Seq2Seq
概要
Seq2seqとは
Seq 2seqは、Encoder-Decoderモデルの一種のことである。時系列データを入力にとって、時系列データを出力するモデルである。
具体的な用途は、機械対話や機械翻訳などに使用されている。
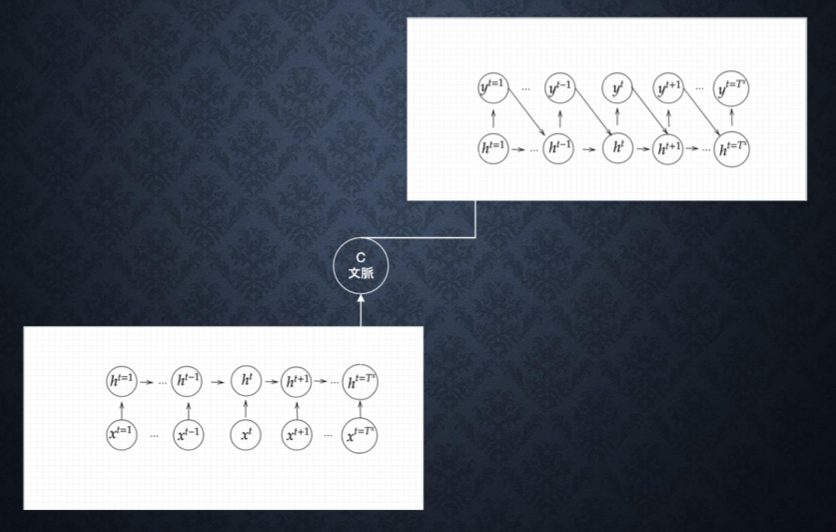
Seq2seqの課題は、一問一答しかできない。すなわち、問に対して文脈も何もなく、ただ応答が行われ続ける。
この課題を解決する手法が、後述するHREDである。
Encoder RNN
ユーザーがインプットしたテキストデータを単語などのトークンに区切って渡す構造である。
Taking
文章を単語などのトークン毎に分割し、トークン毎のIDに分割する。
Embedding
IDから、そのトークンを表す分散表現ベクトルに変換する。
Encoder RNN
ベクトルを順番にRNNに入力していく。
Decoder RNN
システムがアウトプットデータを丹後などのトークン毎に生成する構造である。
HRED(Hierarchical Recurrent Encoder-Decoder)
過去のn-1個の発話から次の発話を生成する。Seq2seqでは、会話の文脈無視で応答がなされたが、HREDでは、前の単語の流れに即して生成されるため、より人間らしい文章が生成される。
HREDの課題
HREDは確率的な多様性が字面にしかなく、会話の「流れ」のような多様性がない。同じコンテキスト(発話リスト)を与えても、答えの内容が毎回会話の流れとしては同じものしか出せない。また、HREDは短く情報量に乏しい答えをしがちである。
VHRED (Latent Variable Hierarchical Recurrent Encoder-Decoder)
HREDの課題をVAEの潜在変数の概念を追加することで解決した構造である。
VAE(Variational Auto-Encoder)
オートエンコーダ
教師なし学習の一つ。そのため学習時の入力データは訓練データのみで教師データは利用しない。
オートエンコーダの構造
入力データから潜在変数$z$に変換するニューラルネットワークをEncoder、逆に潜在変数$z$をインプットとして元画像を復元するニューラルネットワークをDecoder、から構成される。
オートエンコーダを使うと次元削減が行える。$z$の次元が入力データより小さい場合、次元削減と見なすことができる。
確認テスト
seq2seqについて説明している選択肢は?
- 時刻に関して順方向と逆方向のRNNを構成し、それら2つの中間層表現を特徴量として利用するものである。
- RNNを用いたEncoder-Decoderモデルの一種であり、機械翻訳などのモデルに使われる。
- 構文木などの木構造に対し、隣接単語から表現ベクトル(フレーズ)を作るという演算を再帰的に行い(重みは共通)、分全体の表現ベクトルを得るニューラルネットワークである。
- RNNの一種であり、単純なRNNにおいて問題になる勾配損失問題をCECとゲートの概念を導入することで解決したものである。
正解は2である。(1は双方向RNN、3は構文木、4はLSTMに関する説明である)
seq2seqとHRED、HREDとVHREDの違いを簡潔に述べよ
seq2seqとHREDの違い
Seq2Seqは一問一答しかできない(問に対して文脈も何もなく、ただ応答が行われ続ける) が、HREDは過去n−1個の発話から文脈に応じた回答ができる。
HREDとVHREDの違い
HREDは発話に多様性がなく情報量に乏しいが(うん、そうだねなど単調になる) 、VHREDはそれらの課題を解決し、文脈を保持しながら多様性ある発話ができる。
VAEに関する説明文中の空欄(下線部分)に言葉を埋め、説明文を完成させる
「自己符号化器の潜在変数に確率変数を導入したもの。」
実装演習
本節では、実装演習は無し。
Section6:Word2vec
概要
RNNでは、単語のような可変長の文字列をNNに与えることはできない。固定長形式で単語を表現する必要がある。
word2vecは、学習データからボキャブラリを作成するものである。
例えば、次のような文章があった場合のボキャブラリは次のようになる。
I want to eat apples. I like apples. → {apples, eat, I, like, to, want}
applesを入力する場合、入力層には以下のベクトルが入力される。本来は辞書の単語数だけone-hotベクトルができる。
1,,,apples
0,,,eat
0,,,I
0,,,like
0,,,to
…
このように表現することにより、大規模データの分散表現の学習が、現実的な計算速度とメモリ量で実現可能となる。
確認テスト
確認テストなし。
実装演習
実装実習なし。
Section7:Attention Mechanism
概要
Seq2seqの問題は長い文章への対応が難しいことである。Seq2seqでは、2単語でも100単語でも、固定次元ベクトルの中に入力しなければならない。
そのため、文章が長くなるほどそのシーケンスの内部表現の次元も大きくなっていく仕組みが必要となる。
Attention Mechanism(Attention機構)は、「入力と出力のどの単語が関連しているのか」の関連度を学習する仕組みである。
確認テスト
RNN、Word2Vec、Seq2Seq、Attentionの違いを簡潔に述べよ
RNN
時系列データを処理するのに適したネットワーク。
Word2Vec
単語の分散表現ベクトルを得る手法。
Seq2Seq
ある時系列データから別の時系列データを得る手法。
Attention
時系列データの中身それぞれに重みをつける手法。
実装演習
実装実習なし。
深層学習day4
Section1:強化学習
概要
強化学習とは
長期的に報酬を最大化できるように環境の中で行動を選択できるエージェントを作ることを目標とする機械学習の一分野である。
行動の結果として与えられる利益(報酬)をもとに、行動を決定する原理を改善していく仕組みである。
強化学習イメージ
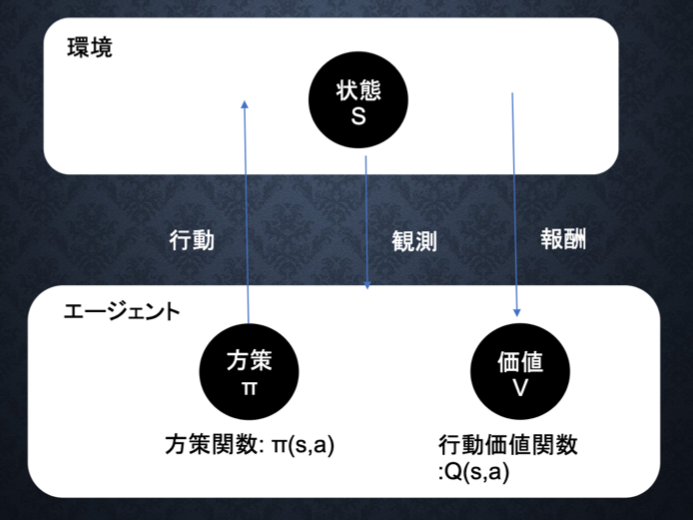
強化学習の応用例
マーケテイングの場合、次のように対応する。
-
環境:会社の販売促進部。
-
エージェント:プロフィールと購入履歴に基づいて、キャンペーンメールを送る顧客を決めるソフトウェアのこと。
-
行動:顧客ごとに送信、非送信のふたつの行動を選ぶこと。
-
報酬:【負の報酬】キャンペーンのコスト 【正の報酬】キャンペーンで生み出されると推測される売り上げ
検索と利用のトレードオフ
環境について事前に完璧な知識があれば、最適な行動を予測し決定することは可能である。先のマーケティングの例では、どのような顧客にキャンペーンメールを送信すると、どのような行動を行うのかが既知である状況。
しかしながら、強化学習の場合、上記仮定は成り立たないとする。不完全な知識を元に行動しながら、データを収集。最適な行動を見つけていく。
過去データからベストな行動をとり続けるともっとベストな行動をとれず、未知な行動のみをとり続けると過去のデータを生かせないという関係がある。
強化学習の差分
強化学習と通常の教師あり、教師なし学習の違いについて述べる。
- 教師あり、教師なし学習では、データに含まれるパターンを見つけ出し、予測するのが目標。
- 強化学習では、優れた方策を見つけるのが目標。
価値関数
価値関数には次の 2種類がある。
- 状態価値関数:ある状態の価値に注目する
- 行動価値関数:状態と価値の組み合わせた価値に注目する
方策関数
方策ベースの強化学習において、エージェントがどんな行動をとるのかを決める関数のこと。
方策勾配法
方策をモデル化して最適化する手法であり、次のように定義される。 $$ \theta^{(t+1)} = \theta^{(t)} + \epsilon \nabla J(\theta) $$ 上記の定義に対応し、行動価値関数$Q(s,a)$の定義を行い、次の方策勾配定理が成り立つ。 $$ \nabla_{\theta} J(\theta) = \mathbb{E}{\pi{\theta}}[(\nabla_{\theta}\log \pi_{\theta}(a|s)Q^{\pi}(s,a))] $$
確認テスト
なし。
実装演習
なし。
Section2:AlphaGo
概要
AlphaGoにAlphaGo LeeとAlphaGo Zeroがある。
AlphaGo Lee
AlphaGo LeeはPolicyNetとValueNetの2つのネットワークが登場し、ともに畳み込みニューラルネットワークになっている。PolicyNetが強化学習での方策関数で、ValueNetが価値関数である。PolicyNetでは、48チャンネルある19×19の盤面の特徴を入力し、19×19マスの着手予想確率が出力される。ValueNetでは、49チャンネルある19×19の盤面の特徴を入力し、現局面の勝率を-1~1で表したものが出力される。
AlphaGoの学習は次のステップで行われる。
- 教師あり学習によるRollOutPolicyとPolicyNetの学習
- 強化学習によるPolicyNetの学習
- 強化学習によるValueNetの学習
AlphaGo Zero
教師あり学習を一切なくし、最低限のルールのみを与えて、あとは報酬が最大になるようにゼロから学習させたモデルである。AlphaGo Zeroは3日でAlphaGo Leeの強さを超えた。人間の経験則を教えないで学ばせた方が、未知の手が生み出されて良いことを示唆している。
AlphaGo LeeとAlphaGo Zeroの違い
- 教師あり学習を一切行わず、強化学習のみで作成
- 特徴入力からヒューリスティックな要素を排除し、石の配列のみにした
- PolicyNetとValueNetを一つのネットワークに統合した
- Residual Netを導入した
- モンテカルロ木探索からRollOutシミュレーションをなくした
確認テスト
なし。
実装演習
なし。
Section3:軽量化・高速化技術
概要
分散深層学習
深層学習は多くのデータを使用したり、パラメータ調整のために多くの時間を使用したりするため、高速な計算が求められる。複数の計算資源(ワーカー)を使用し、並列的にニューラルネットを構成することで、効率の良い学習を行うことが必要となる。そのための代表的な技術としては次の通り。
- データ並列化
- モデル並列化
- GPUによる高速技術
データ並列化
親モデルを各ワーカー(計算資源)に子モデルとしてコピーする。データを分割し、各ワーカーごと計算させ、最終的にデータをマージする手法。同期型と非同期型がある。
同期型
各ワーカーが計算が終わるのを待ち、全ワーカーの勾配が出たところで勾配の平均を計算し、親モデルのパラメータを更新する
非同期型
各ワーカーはお互いの計算を待たずに、各子モデルごとに更新を行う。学習が終わった子モデルはパラメータサーバにpushされる。新たに学習を始める時は、パラメータサーバからpopしたモデルに対して学習していく。
同期型と非同期型の比較
- 処理のスピードは、お互いのワーカーの計算を待たない非同期型の方が早い。
- 非同期型は最新のモデルのパラメータを利用できないので、学習が不安定になりやすい。
- 現在は同期型の方が精度が良いことが多いので、主流となっている。
モデル並列化
親モデルを各ワーカーに分割し、それぞれのモデルを学習させる。全てのデータで学習が終わった後で、一つのモデルに復元する。モデルが大きいときはモデル並列化を、データが多い時はデータ並列化をすると良い。
モデルのパラメータ数が多いほど、スピードアップの効率も向上する。
GPUによる高速化
GPUは元々グラフィック描画のため、比較的低性能なコアを多数用意することで、グラフィック描画を高速処理するためのプロセッサユニットである。ニューラルネットの学習は単純な行列計算が多く、グラフィック描画処理においてもアフィン変換など行列計算が多用され類似性が高く、GPUと相性が良い。
NVIDIAがCUDAというGPU上で並列コンピューティングを行うためのプラットフォームを開発し、GPGPU(General Purpos on GPU)として2010年頃から脚光を浴び始めた。丁度、2012年ILSVRCでAlexNetでもGPUが処理の分散・高速化のため使われ、今日では深層学習でGPUが当然のように用いられている。
モデルの軽量化
モデルの軽量化とは、モデルの精度を維持しつつパラメータや演算回数を低減するための手法の総称である。モデルの軽量化は、モバイル、IOT機器において有効な手法である。
軽量化の代表的な手法として、次の3つがある。
- 量子化
- 蒸留
- プルーニング
量子化(Quantization)
ネットワークが大きくなると大量のパラメータが必要となり、学習や推論に多くのメモリと演算処理が必要となる。そのため、パラメータを64ビット(FP64)浮動小数点ではななく、32ビット(FP32)などより精度を落として表現し、メモリと演算処理の削減を行う。
NVIDIAの最新GPU(Ampereアーキテクチャ)では、テンソル演算に特化したTF32(19ビットで表現)というフォーマットをサポートし、メモリの圧縮、処理高速化を図っている。
蒸留(Distillation)
精度の高いモデルはニューロンの規模が大きなモデルになっている。そのため、推論に多くのメモリと演算処理が必要となる。規模の大きなモデルの知識を使い軽量なモデルの作成を行うことを蒸留という。
蒸留は、教師モデルと生徒モデルの 2つで構成される。
- 教師モデル 予測精度の高い、複雑なモデルやアンサンブルされたモデル
- 生徒モデル 教師モデルをもとに作られる軽量なモデル。
プルーニング(Pruning)
ネットワークが大きくなると大量のパラメータが必要となるが全てのニューロンの計算が精度に寄与しているわけではない。モデルの精度への寄与が少ないニューロンを削減することでモデルの軽量化、高速が図る手法がプルーニングである。
確認テスト
なし。
実装演習
なし。
Section4:応用技術
概要
MobileNet
MobileNetsでは畳み込み層の内積回数とパラメータ数を減らすことで、推論速度の改善を実現している。そのため、次の2つがコアなアイディアとなっている。
- Depthwise separable convolutionsで計算量を削減
- 精度と速度のトレードオフを調整するハイパパラメータの導入
DenseNet
Dense NetはResNetを改善したモデルで、従来よりコンパクトなモデルにもかかわらず、高い性能を持つことが特徴である。ショートカット接続をたくさん入れることで、層間の情報伝達をしやすくしている。
特徴はDense Blockという部分があるのが特徴である。このブロックを通るたびに、画像のチャネルがどんどん増えていく。具体的には、前スライドで計算した出力に入力特徴マップを足し合わせる。チャネル数が増えすぎても困るので、畳み込み層とプーリング層でチャネル数を減らす動作を行う。
Batch Norm Layer
レイヤー間を流れるデータの分布を、ミニバッチ単位で平均0、分散1になるように正規化する手法。Batch Normalizationはニューラルネットワークにおいて学習時間の短縮や初期値への依存低減、過学習の抑制などの効果がある。
問題点として、Batch sizeが小さい条件下では、学習が収束しないことがあり、代わりにLayerNormなどの正規化手法が使われることが多い。
Layer Norm
BatchNormとLayerNormでは、正規化の仕方が異なる。
- BatchNormは複数の同チャネルごとに正規化する。
- LayerNormでは画像ごとに正規化を行う。入力データのスケールや、重み行列のスケール・シフトに対してロバストになることが知られている。
Instance Norm
Instance Normは、各サンプルの各チャネルごとに正規化を行う。
Wavenet
Wavenetは音声生成モデルとなる。時系列データに対して畳み込み(Dilated convolution)を適用している。層が深くなるにつれて畳み込むリンクを離すということを行っている。これによってより長い範囲の情報をうまく使えるようにしている。
確認テスト
MobileNetのアーキテクチャ
- Depthwise Separable Convolutionという手法を用いて計算量を削減している。通常の畳み込みが空間方向とチェネル方向の計算を同時に行うのに対して、Depthwise Separable ConvolutionではそれらをDepthwise ConvolutionとPointwise Convolutionと呼ばれる演算によって個別に行う。
- Depthwise Convolutionはチャネル毎に空間方向に畳み込む。すなわち、チャネル毎に$D_k\times D_k\times 1$のサイズのフィルターをそれぞれ用いて計算を行うため、その計算量は__($H \times W \times C \times K \times K$)__となる。
- 次にDepthwise Convolutionの出力をPointwise Convolutionによってチャネル方向に畳み込む。すなわち、出力チャネル毎に$1\times 1 \times M$サイズのフィルタをそれぞれ用いて計算を行うため、その計算量は__($H \times W \times C \times M$)__となる。
Wavenet
深層学習を用いて結合確率を学習する際に、効率的に学習が行えるアーキテクチャを提案したことがWaveNetの大きな貢献の一つである。
提案された新しいConvolution型アーキテクチャは(Dilated causal convolution)と呼ばれ、結合確率を効率的に学習できるようになっている。
__(Dilated causal convolution)を用いた際の大きな利点は、単純なConvolution layerと比べて(パラメータ数に対する受容野が広い)__ことである。
実装演習
なし。
Section5:Transformer
概要
本セクションでは、Encoder-Decoderモデル(Seq2seq )、Transformerを学び、BERTを理解することが狙いである。
Seq2seq
- Seq2seqは、系列(sequence)を入力として、系列を出力するものであり、Encoder-Decoderモデルとも呼ばれる。
- 入力系列がEncode(内部状態に変換)され、内部状態からDecode(系列を変換)する。
- 系列情報の例
- 翻訳(英語 → 日本語)
- 音声認識(波形 → テキスト)
- チャットボット(テキスト → テキスト)
下図のように、2つのRNNが連結されている。左側のRNNがEncoder、右側のRNNがDecoderである。
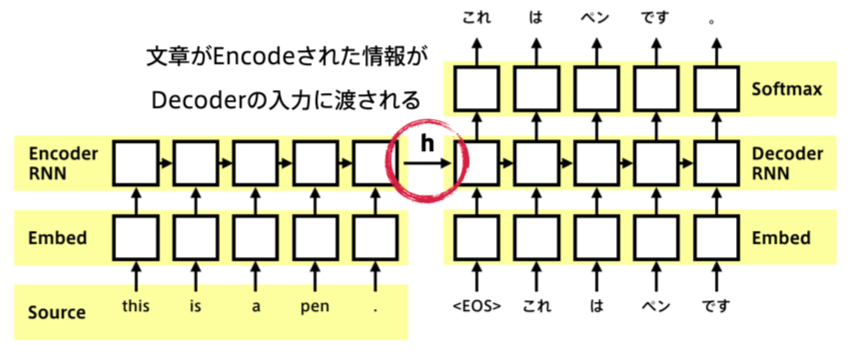
Encoder
入力として自然文が与えられると、内部状態ベクトル$\boldsymbol{h}$が出力される。
Decoder
隠れ状態の初期値にEncoder側から$\boldsymbol{h}$を受け取る。
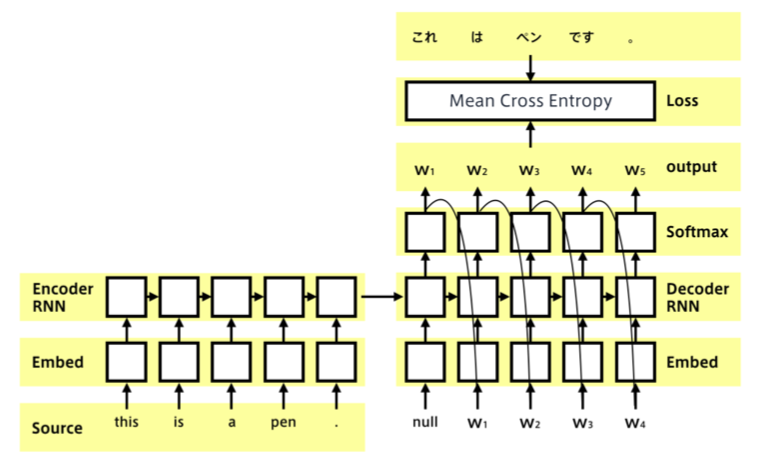
Decoderのoutput側に正解を当てれば教師あり学習がEnd2endで行える。
Transformer
Encoder-Decoderモデルの問題点
Encoder-Decoderモデル(ニューラル機械翻訳)は、翻訳元の内容をひとつのベクトルで表現しており、文が長くなると表現力が足りなくなる。
Attention(注意機構)
上記のSeq2seqの問題を解決したのが、Attention付きSeq2seqである。
AttentionはそれまでEncoder部分から作られる固定長ベクトルが最後の部分しか利用されていなかった点に着目し、各単語が入力される際に出力される固定長ベクトルをすべて利用することで
- 単語の数と同じ数だけの固定長ベクトルを獲得することができ(文章の長さに応じた情報量を獲得することができる)
- そのことで各単語間の照応関係(アライメント)を獲得すること
を可能にした。(これは、各単語を入力したときに出力される固定長ベクトルには、最後に入力された単語の情報が強く反映される傾向があることを利用したものである。)
Transformer
2017年6月、GoogleからAttention is All You Needとの論文が発表された。日本語による解説記事はこのページ。
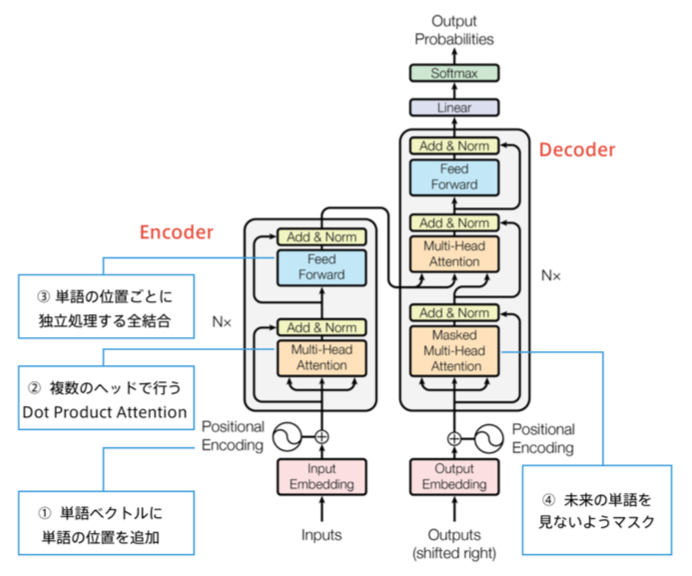
Transformerは、RNNやCNNを使わずAttentionのみ使用したニューラル翻訳である。わずかな訓練で圧倒的な性能を達成(WMT'14 の BLEU スコアは英仏: 41.0, 英独: 28.4 で第 1 位)した。
確認テスト
なし。
実装演習
なし。
Section6:物体検知・セグメンテーション
概要
広義の物体認識タスク

代表的データセット
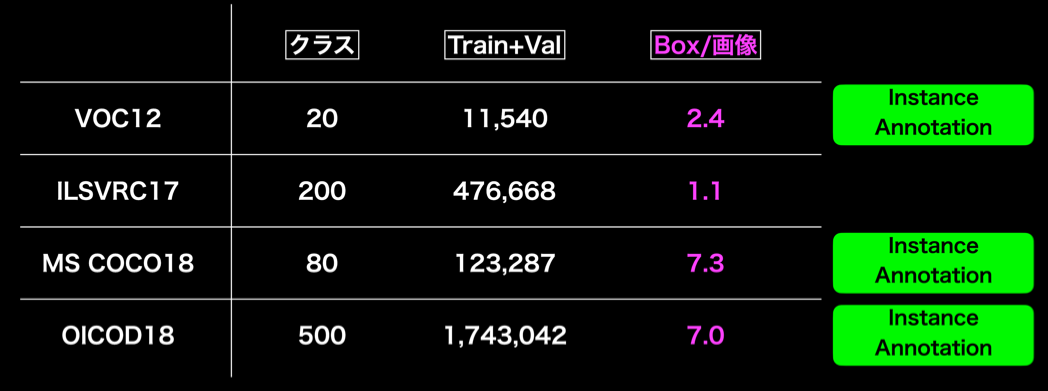
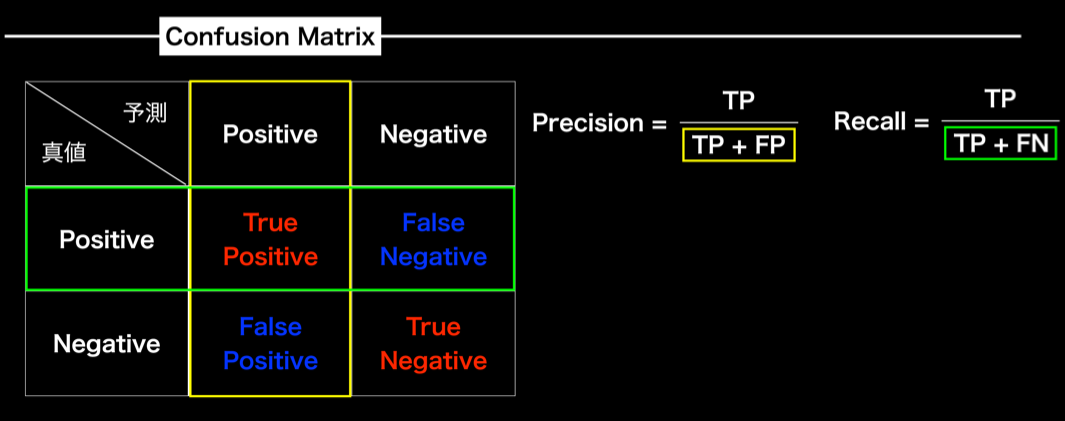
分類問題における評価指標
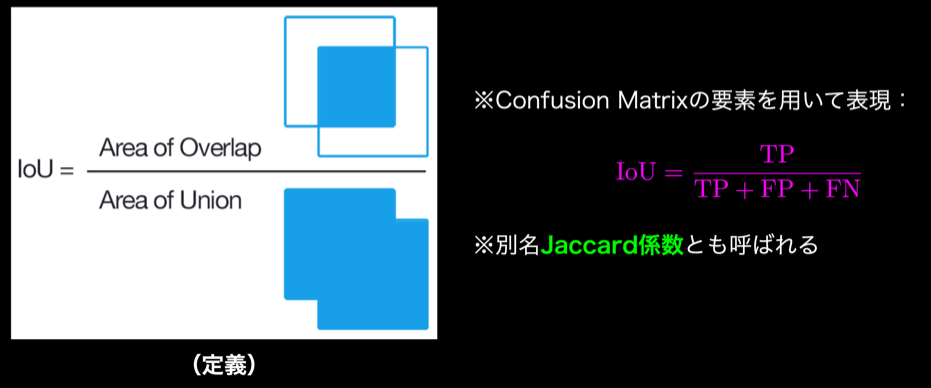
IoU(Intersection over Union)
物体検出においてはクラスラベルだけでなく、物体位置の予測精度も評価したいので、それをConfusion Matrixの要素を用いて表現したものをIoU(Intersection over Union)である。IoUの定義は、以下の通り。
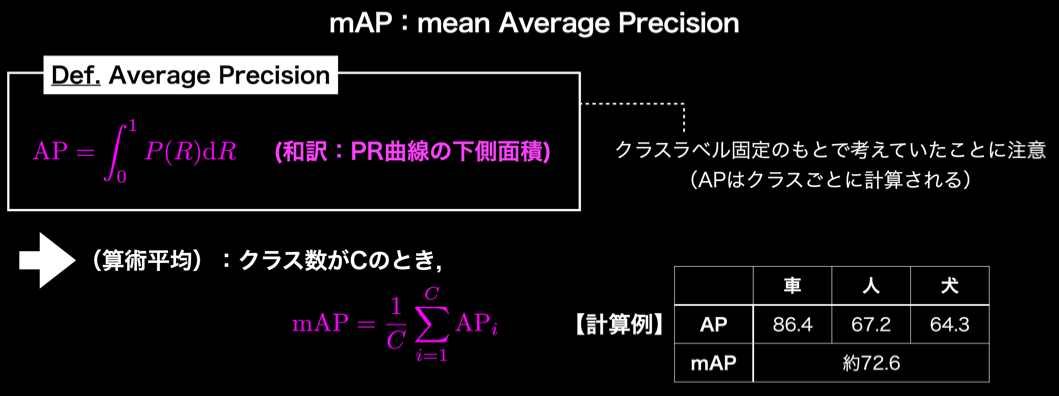
mAP(mean Average Precision)
物体検出のフレームワーク
- 2段階検出器(Two-stage detector)
- 方向療育の検出とクラス推定を別々に行う
- 相対的に精度が高い傾向
- 相対的に計算量が大きく推論も遅い傾向
- 1段階検出器(One-stage detector)
- 候補領域の検出とクラス推定を同時に行う
- 颯太的に精度が低い傾向
- 相対的に計算量が小さく推論も早い傾向
SSD(Single Shot Detector)
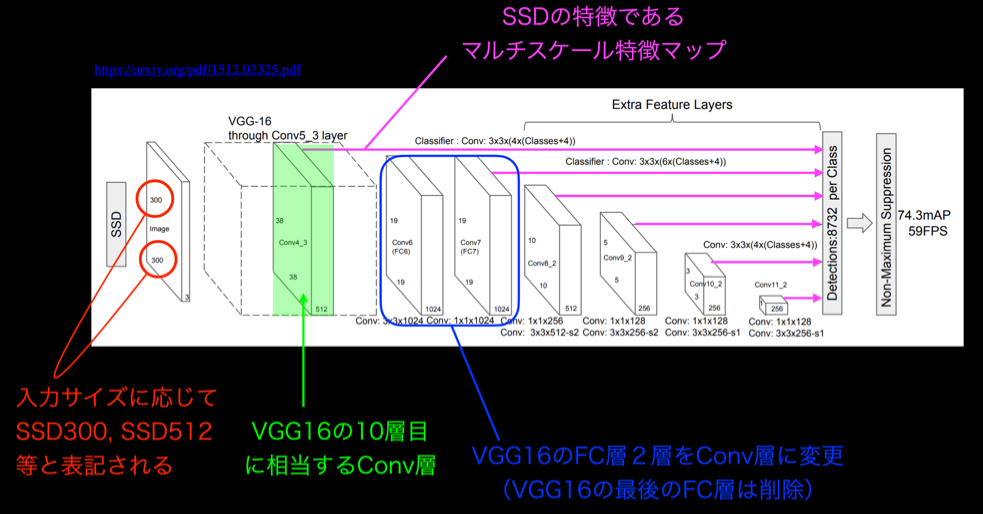
SSD(Single Shot Detector)の肝となるのは、「デフォルトボックス(default boxes)」という長方形の「枠」である。 一枚の画像をSSDに読ませ、その中のどこに何があるのか予測させるとき、SSDは画像上に大きさや形の異なるデフォルトボックスを8732個乗せ、その枠ごとに予測値を計算する。
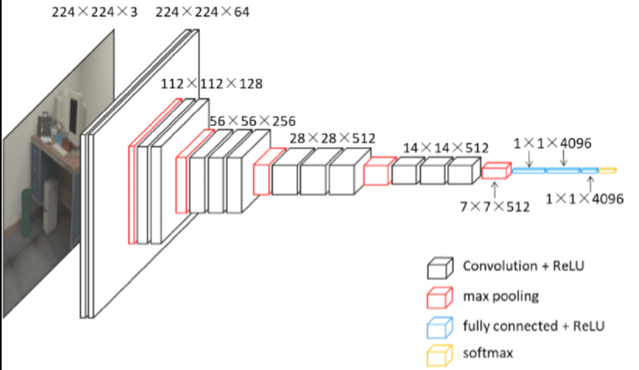
ILSVRC CLS-LOCデータセットで事前に訓練された、下図のVGG16をベースにしている。
SSDのネットワークアーキテクチャは、下図の通りである。
SS(Semantic Segmentation)
アップサンプリングの壁
コンボリューション+プーリングを経ることで解像度が下がっていくので、SSを行うためにはアップサンプリングが必要になる。
そもそも、プーリングなんてしなければよいのでは? という疑問が湧く! 以下はその答えである。
- 正しく認識するためには受容野にある程度の大きさが必要
- 受容野を広げるためには、以下の2つのやり方がある
- 深いConvolution層を用意する
- プーリング(ストライド)
深いConvolution層を用意すると、演算量の増大、大容量メモリを必要となる。
確認テスト
なし。
実装演習
なし。