モチベーション
この記事でDCGANを実行し、これまで使っていたGTX 1080と比べ、新たに導入したRTX A4000が、体感的に速くなったと書いた。 また、自分の環境では、jupyterlabのnotebookをNFSサーバーに置いて、複数のサーバから使っている(同時実行は無しとの運用で)。以前から、notebookをローカル環境に置くと速くなると感じていた。
今回は、GTX 1080/RTX A4000、NFS/ローカルの組み合わせで、実アプリの実行速度を計測する。
実行環境
先ず最初に断っておくべきこととして、厳密な意味での性能比較ではなく、自身の使っている環境下で同じアプリの実行時間の差異を計測したものであること。
自分の実行環境は、次の図のとおり。
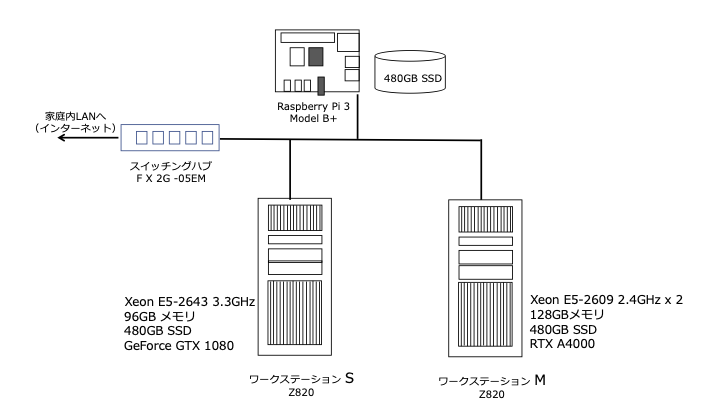
singularityコンテナ(.sifファイル)およびjupyterlabのnotebook(ipynbファイル)は、Raspberry PiのSSD(USB接続)に格納し、各ワークステーションからNFSマウント。
singuralityコンテナを起動する際に、NFSマウントしているnotebookを使うか、ローカルディレクトリのnotebookを使うかは、次の起動コマンドで「–bind」オプションを使って切り分けている。 ここで「COMMON_AREA」はNFSマウント先である。(.bashrcで定義済)
1)NFSマウントのnotebookを使用
export SINGULARITYENV_CUDA_VISIBLE_DEVICES=0
singularity run --nv --bind ${COMMON_AREA}/jupyterlab:/workdir ${COMMON_AREA}/sifs/pytorch-lab.sif
2)ローカルディレクトのnotebookを使用
export SINGULARITYENV_CUDA_VISIBLE_DEVICES=0
singularity run --nv --bind ${HOME}/jupyterlab:/workdir ${COMMON_AREA}/sifs/pytorch-lab.sif
計測したアプリ
計測した実アプリは、これまでも何度も述べてきたこのDCGANの中で、学習エポック全体の実行時間を計測した。次のように学習ループの前にタイマーをセットし、ループ終了時の時間との差により実行時間とした。
このコードの前で、使用するセレブのイメージデータをデータセットにし、データローダを実行している。また「import time」を追加している。
# === Training Loop ===
# Lists to keep track of progress
img_list = []
G_losses = []
D_losses = []
iters = 0
print("Starging Training Loop...")
start_time = time.time() # 実行時間計測開始
# For each epoch
for epoch in range(num_epochs):
# For each batch in the dataloader
for i ,data in enumerate(dataloader, 0):
# (1) Update D network; maximize log(D(x))+log(1-D(G(z)))
# Train with all-real batch
netD.zero_grad() # Sets gradients of all model parameters to zero.
# Format batch
real_cpu = data[0].to(device)
b_size = real_cpu.size(0)
label = torch.full((b_size,), real_label, dtype=torch.float, device=device)
# Forward pass real batch through D
output = netD(real_cpu).view(-1)
# Calculate loss on all-reaal batch
errD_real = criterion(output, label)
# Calculate gradients for D in backward pass
errD_real.backward()
D_x = output.mean().item()
# Train with all-fake batch
# Generate batch of latent vectors
noise = torch.randn(b_size, nz, 1, 1, device=device)
# Generate fake image batch with G
fake = netG(noise)
label.fill_(fake_label)
# Classify all fake batch with D
output = netD(fake.detach()).view(-1)
# Calculate D's loss on the all-fake batch
errD_fake = criterion(output, label)
# Calculate the gradients for this batch
errD_fake.backward()
D_G_z1 = output.mean().item()
# Add the gradients from the all-real and all-fake batch
errD = errD_real + errD_fake
# Update
optimizerD.step()
# (2) Update G network: maximize log(D(G(z)))
netG.zero_grad()
label.fill_(real_label) # fake labels are real for generator cost
# Since we just updated D, perform another foward passs all-fake batch through D
output = netD(fake).view(-1)
# Calculate G's loss based on this output
errG = criterion(output, label)
# Calculate gradients for G
errG.backward()
D_G_z2 = output.mean().item()
# Update
optimizerG.step()
# Output training stats
if i % 50 == 0:
print('[%d/%d][%d/%d]\tLoss_D: %.4f\tLoss_G: %.4f\tD(x): %.4f\tD(G(z)): %.4f / %.4f'
% (epoch, num_epochs, i, len(dataloader),
errD.item(), errG.item(), D_x, D_G_z1, D_G_z2))
# Save losses for plotting later
G_losses.append(errG.item())
D_losses.append(errD.item())
# Check how the generator is doing by saving G's output on fixed_noise
if (iters % 500 ==0) or ((epoch == num_epochs-1) and (i == len(dataloader)-1)):
with torch.no_grad():
fake = netG(fixed_noise).detach().cpu()
img_list.append(utils.make_grid(fake,padding=2, normalize=True))
iters += 1
lapse_time = time.time() - start_time
print("-" * 80)
print("実行時間 {:8.2f}秒".format(lapse_time))
print("-" * 80)
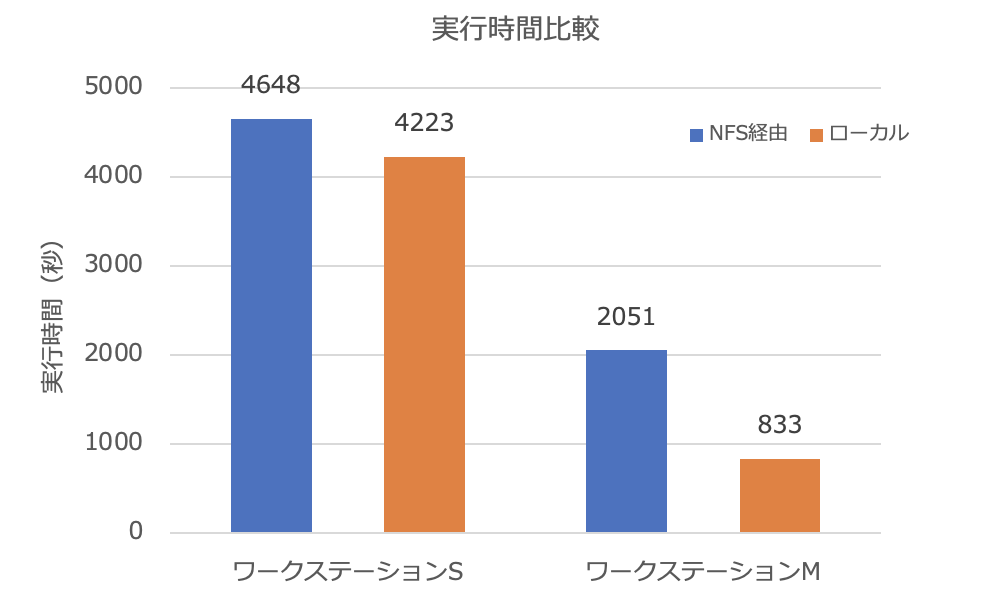
計測結果
notebookをNFSマウント先とローカルディレクトリにおいて、各々を3回実行した平均値(秒)は、以下の通り。
| NFS経由 | ローカル | |
|---|---|---|
| ワークステーション S | 4648 | 4223 |
| ワークステーション M | 2051 | 833 |
まとめ
最初に断った通り、同じ環境下でGPUのみの差を表す性能測定ではない。条件も異なるワークステーションでの実行時間を比較したものではあるが、RTX A4000を搭載したワークステーションMが実行速度は、2〜5倍向上している。2倍は価格差を吸収できていないが、5倍だったら価格差分の実行速度向上と言える。
RTX 1080を使っている範囲では、NFSを利用してもネットワークは律速(ボトルネック)にならないが、A4000においては、ネットワーク等のI/O性能が全体の律速となっている。
NFSの性能を今後測定してみたい。