モチベーション
この記事で、DCGANのアプリの実行時間を測定した、その際に、notebookをローカルディレクトリ、NFSマウント先に配置して実行速度を測定した。性能が高いGPUを使った場合、ローカルに比較してNFS経由が遅かったので、ローカルファイルとNFSファイルのリード/ライトで、どの程度の差があるのか性能測定した。
測定環境
測定したワークステーション、NFSマウント先については、前回の記事の実行環境の通り。
測定に使用したコードは、以下の通り、実行する際に、ローカルディレクトリ、NFSのディレクトリにcdして、このシェルプロを実行した。
4KB/16KB/64KB/256KB/1024KB単位に2GBのファイルをddでwriteし、その後readするもの。
#!/bin/sh
# Disk write
# 4KBx512K回
dd if=/dev/zero of=bench_4K bs=4K count=512K conv=fdatasync
echo "write 4K\n"
# 16KBx128K回
dd if=/dev/zero of=bench_16K bs=16K count=128K conv=fdatasync
echo "write 16K\n"
# 64KBx32K回
dd if=/dev/zero of=bench_64K bs=64K count=32K conv=fdatasync
echo "write 64K\n"
# 256KBx8K回
dd if=/dev/zero of=bench_256K bs=256K count=8K conv=fdatasync
echo "write 256K\n"
# 1024KBx2K回
dd if=/dev/zero of=bench_1024K bs=1024K count=2K conv=fdatasync
echo "write 1024K\n"
# Disk read
# 4KBx512K回
echo 3 > /proc/sys/vm/drop_caches
dd if=bench_4K of=/dev/null bs=4K count=512K
echo "read 4K\n"
# 16KBx128K回
echo 3 > /proc/sys/vm/drop_caches
dd if=bench_16K of=/dev/null bs=16K count=128K
echo "read 16K\n"
# 64KBx32K回
echo 3 > /proc/sys/vm/drop_caches
dd if=bench_64K of=/dev/null bs=64K count=32K
echo "read 64K\n"
# 256KBx8K回
echo 3 > /proc/sys/vm/drop_caches
dd if=bench_256K of=/dev/null bs=256K count=8K
echo "read 256K\n"
# 1024KBx2K回
echo 3 > /proc/sys/vm/drop_caches
dd if=bench_1024K of=/dev/null bs=1024K count=2K
echo "read 1024K\n"
# Clean up created files
rm bench_4K bench_16K bench_64K bench_256K bench_1024K
測定結果
上記の測定用シェルプロを3回実行し、ddの結果として表示される、転送速度(MB/s)の平均値を測定結果とした。
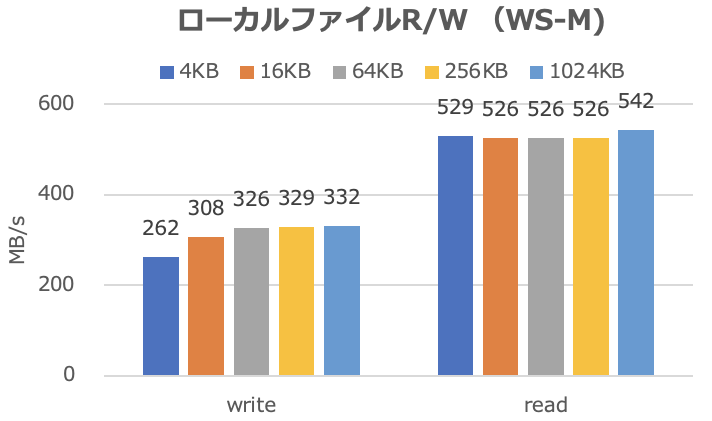
ローカルファイルのリード/ライト
| Write (MB/s) | Read (MB/s) | |
|---|---|---|
| 4KB | 262 | 529 |
| 16KB | 308 | 526 |
| 64KB | 326 | 526 |
| 256KB | 329 | 526 |
| 1024KB | 332 | 542 |
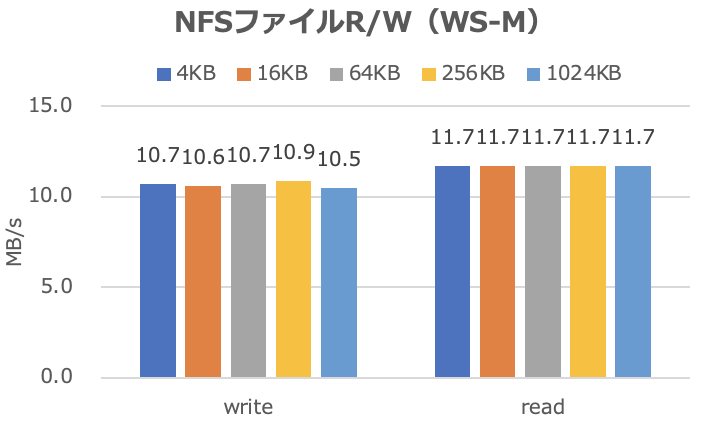
NFSファイルのリード/ライト
| Write (MB/s) | Read (MB/s) | |
|---|---|---|
| 4KB | 10.7 | 11.7 |
| 16KB | 10.6 | 11.7 |
| 64KB | 10.7 | 11.7 |
| 256KB | 10.9 | 11.7 |
| 1024KB | 10.5 | 11.7 |
まとめ
自分の環境において、NFSファイルとローカルファイルのリード/ライトの性能を比較すると、writeで30倍、readで50倍程度の差がある。
NFSは複数ワークステーションでデータ共有するのに便利であるが、ファイル読み書きのあるアプリ実行の場合、ローカル側にデータを置くように、考えた方が良さそうだ。