モチベーション
Kubernetesの勉強を兼ねて、自宅に設定している複数のワークステーションを使って、GPUクラスタを作ることにチャレンジ。
Kubernetesを初めて触った自分には、ハードルが高かった。というのもインストール時にのみ必要な操作か、(運用時の)クラスタ構築時に必要な操作か、を切り分けを資料で学びながらのインストールとなったので。
現状では、GPUクラスタは動作していない! この資料は、未完成です。
情報源
-
本家のドキュメント 先ずは本家のドキュメント。以下に本家のドキュメントでよく参照した部分(日本語中心)。
-
NVIDIAのドキュメント:Install Kubernetes 敢えて、コンテナランタイムとしてcontainerdを使うことにし、資料の「containerd」タグをベースにインストールした。
-
Kubernetes v1.23.6/Nvidia GPUと戯れる コンテナランタイムでDockerを使用するが、貴重な情報が豊富。
-
とある先輩の資料 〜 上記「Kubernetes v 1.23.6/Nvidia GPUと戯れる」をベースにした非公開のインストール資料。とっても良くまとまっていて、読みやすい資料。
-
Kubernetes完全ガイド 第2版 今後の運用などでも参考とするため、最近購入。
インストール概要
方針
上記のNVIDIAのドキュメントを基にしてインストールを進める。選択する部分が2つあるが、「kubeadm」でkubernetesをインストールし、NVIDIA関連のソフトは「NVIDIA GPU Operator」を使うことにした。自分の環境には、driver、NVIDIA Container Toolkitは既にインストール済である。
NVIDIAのドキュメントは、つながり(インデント)が分かり難いので、インストールの全体像を見るため、以下に手順を示す。(項番の各々がNVIDIAドキュメントの各コマンドとほぼ対応している)
環境
kubernetesをインストールする環境は、次の図の通り。
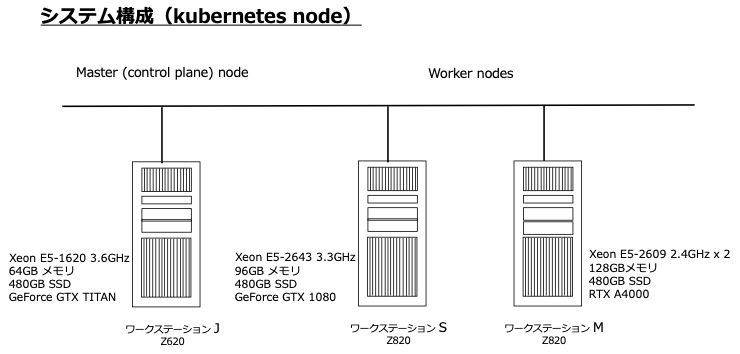
インストール手順
Step 1: container Engineをインストール
(1) containerdに必要なものパッケージをインストール
(2)overlay, br_netfilter(カーネル)モジュールをロードするように設定
(3)sysctlパラメータをconfファイルに設定
(4)Dockerリポジトリを設定
(5)containerdをインストール
(6)containerdのデフォルトパラメータをconfig.tomlを(作成し)設定
(7) (containerdが)systemd cgroup driverを使うように、config.tomlを変更
(8) containerdデーモンを再起動
Step 2: Kubernetesコンポーネントをインストール
(1) 必要なパッケージをインストール
(2) リポジトリキーを追加
(3) リポジトリを追加
(4) kubeletをインストール
(5) Noteの1:Kuberlet 用にcgroupドライバーを設定
(6) Noteの2:kubeletを再起動
(7) swapを無効化
(8) kubeadm initを実行
(9) 認証用ファイルを$HOME配下にコピー
Step 3: ネットワークを設定
(1) Calicoでネットワークを設定
(2) masterにもworker役を割当
Step 4: NVDIAソフトウェアを設定(NVIDIA GPU Operatorを使う)
(1) helmをインストール
(2) NVIDIA Helmリポジトリを追加
(3) GPU Operatorをインストール
ここで、「Bare-metal/Passthrough with pre-installed drivers and NVIDIA Container Toolkit」の「Containerd」の部分を実行。
1) config.tomlを編集
2) helm installを実行
(4) GPU Operatorインストールを確認
(5) サンプルのGPUアプリを起動
master(control plane) nodeとworker nodeの切り分け
前節のインストールの各手順について、どのノードで実行するかを以下に示す。
-
Step 1: (1) 〜 Step 2: (7) master、workerの何のノードでも実施。
-
Step 2: (8) 〜 Step 2: (9) masterノードでのみ実施。workerノードでは、「kuberadm join」を実施。
-
Step 3、Step 4 masterノードでのみ実施。
また、インストール手順の中には、kubeadm環境でクラスタ構築の手順もある。これについては後述。
インスール操作
Step 1: container Engineをインストール
(1) 必要なパッケージをインストール
sudo apt-get update\
> && sudo apt-get install -y apt-transport-https \
> ca-certificates curl software-properties-common
自分の環境では、全て最新バージョンだった。
(2)overlay, br_netfilter(カーネル)モジュールをロードするように設定
$ cat <<EOF | sudo tee /etc/modules-load.d/containerd.conf
> overlay
> br_netfilter
> EOF
$ sudo modprobe overlay \
> && sudo modprobe br_netfilter
(3)sysctlパラメータをconfファイルに設定
$ cat <<EOF | sudo tee /etc/sysctl.d/99-kubernetes-cri.conf
> net.bridge.bridge-nf-call-iptables = 1
> net.ipv4.ip_forward = 1
> net.bridge.bridge-nf-call-ip6tables = 1
> EOF
$ sudo sysctl --system
(4)Dockerリポジトリを設定
$ curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key --keyring /etc/apt/trusted.gpg.d/docker.gpg add -
$ sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu \
> $(lsb_release -cs) \
> stable"
(5)containerdをインストール
$ sudo apt-get update \
> && sudo apt-get install -y containerd.io
自分の環境では、containerd.ioは最新バージョン(1.6.7-1)がインストール済だった。
(6)containerdのデフォルトパラメータをconfig.tomlを(作成し)設定
$ sudo mkdir -p /etc/containerd \
> && sudo containerd config default | sudo tee /etc/containerd/config.toml
既にcontainerd.ioがインストール済だったので、/etc/containerdディレクトリ、config.tomlは既に存在していた。config.tomlはリネームして保存しておいた。
(7) (containerdが)systemd cgroup driverを使うように、config.tomlを変更
上記で作成された/etc/containerd/config.tomlを次のように修正。
125c125
< SystemdCgroup = true
---
> SystemdCgroup = false
(8) containerdデーモンを再起動
$ sudo systemctl restart containerd
Step 2: Kubernetesコンポーネントをインストール
(1) 必要なパッケージをインストール
$ sudo apt-get update \
> && sudo apt-get install -y apt-transport-https curl
自分の環境では最新版がインストールされていた。
(2) リポジトリキーを追加
$ curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg | sudo apt-key add -
(3) リポジトリを追加
$ cat <<EOF | sudo tee /etc/apt/sources.list.d/kubernetes.list
> deb https://apt.kubernetes.io/ kubernetes-xenial main
> EOF
(4) kubeletをインストール
$ sudo apt-get update \
> && sudo apt-get install -y -q kubelet kubectl kubeadm
(5) Noteの1:Kuberlet 用にcgroupドライバーを設定
NVIDIAのドキュメントでは、Noteの項番1の箇所。
この時点で既に、/etc/systemd/system/kuberlet.service.d配下に10-kubeadm.confが既に存在。
$ sudo cat << EOF | sudo tee /etc/systemd/system/kubelet.service.d/0-containerd.conf
> [Service]
> Environment="KUBELET_EXTRA_ARGS=--container-runtime=remote --runtime-request-timeout=15m --container-runtime-endpoint=unix:///run/containerd/containerd.sock --cgroup-driver='systemd'"
> EOF
(6) Noteの2:kubeletを再起動
$ sudo systemctl daemon-reload \
> && sudo systemctl restart kubelet
(7) swapを無効化
$ swapon --show
NAME TYPE SIZE USED PRIO
/swapfile file 2G 0B -2
$ sudo swapoff -a
$ swapon --show
$
上記の操作は一時的なもので、サーバを再起動すると再びswapが有効な状態。 永続的に無効化するためには、/etc/fstabの「swap」を含むの行の行頭に#を挿入し、無効化する。 (自分の環境では、/swapfileから始まる行)
(8) kubeadm initを実行
$ sudo kubeadm init --pod-network-cidr=192.168.0.0/16
[init] Using Kubernetes version: v1.24.3
・・・省略・・・
Then you can join any number of worker nodes by running the following on each as root:
kubeadm join 192.168.11.3:6443 --token 7ffwr1.xm119vzqvmhqgevl \
--discovery-token-ca-cert-hash sha256:5d2f3065e38020b668ba1b766d95aea197182e35143511db7062f247f12c81d3
$
最後の「kubeadm join … sha256…」の部分はメモっておくこと。worker nodeとするワークステーションで、次のように実行することで、クラスタを作成できる。
$ sudo kubeadm join 192.168.11.3:6443 --token 7ffwr1.xm119vzqvmhqgevl \
> --discovery-token-ca-cert-hash sha256:5d2f3065e38020b668ba1b766d95aea197182e35143511db7062f247f12c81d3
[preflight] Running pre-flight checks
・・・省略・・・
This node has joined the cluster:
* Certificate signing request was sent to apiserver and a response was received.
* The Kubelet was informed of the new secure connection details.
Run 'kubectl get nodes' on the control-plane to see this node join the cluster.
(9) 認証用ファイルを$HOME配下にコピー
$ mkdir -p $HOME/.kube \
> && sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config \
> && sudo chown $(id -u):$(id -g) $HOME/.kube/config
Step 3: ネットワークを設定
(1) Calicoでネットワークを設定
$ kubectl apply -f https://docs.projectcalico.org/manifests/calico.yaml
(2) masterにもworker役を割当
NVIDIAドキュメントに「最も単純化したsingle-nodeクラスターに、GPU Podをスケジューリングできる」とある通り、master(control plane) nodeにもPodをスケジューリングできるようになる。
$ kubectl taint nodes --all node-role.kubernetes.io/master-
自分の環境では、master nodeにはPodをスケジューリングさせたくなかったので、これは実行していない。
ここまでで、master(control plane) node(kubeadm init操作)とworker node(kubeadm join操作)を各々の1つ構築した状態となる。自分の環境でのnodeの状態は次のとおり。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
jupiter Ready control-plane 109m v1.24.3
saisei Ready <none> 2m42s v1.24.3
更にもう1台をkubeadmin join操作すると、次のような状態。
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
jupiter Ready control-plane 168m v1.24.3
mokusei Ready <none> 2m3s v1.24.3
saisei Ready <none> 62m v1.24.3
Step 4: (GPU Operatorで)NVDIAソフトウェアを設定
(1) helmをインストール
$ curl -fsSL -o get_helm.sh https://raw.githubusercontent.com/helm/helm/master/scripts/get-helm-3 \
> && chmod 700 get_helm.sh \
> && ./get_helm.sh
(2) NVIDIA Helmリポジトリを追加
$ helm repo add nvidia https://helm.ngc.nvidia.com/nvidia \
> && helm repo update
(3) GPU Operatorをインストール
概要の部分でも述べたが、「Bare-metal/Passthrough with pre-installed drivers and NVIDIA Container Toolkit」の「Containerd」の部分を実行。
1) config.tomlを編集
/etc/containerd/config.tomlを次のように編集。
79c79
< default_runtime_name = "nvida"
---
> default_runtime_name = "runc"
125,132d124
< SystemdCgroup = true
< [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia]
< privileged_without_host_devices = false
< runtime_engine = ""
< runtime_root = ""
< runtime_type = "io.containerd.runc.v1"
< [plugins."io.containerd.grpc.v1.cri".containerd.runtimes.nvidia.options]
< BinaryName = "/usr/bin/nvidia-container-runtime"
その後、containerdデーモンを再起動。
$ sudo systemctl restart containerd
2) helm installを実行
$ helm install --wait --generate-name \
> -n gpu-operator --create-namespace \
> nvidia/gpu-operator \
> --set driver.enabled=false \
> --set toolkit.enabled=false
(4) GPU Operatorインストールを確認
$ kubectl get pods -n gpu-operator
NAME READY STATUS RESTARTS AGE
gpu-operator-1660956347-node-feature-discovery-master-78498fqrv 0/1 ContainerCreating 0 22m
gpu-operator-1660956347-node-feature-discovery-worker-d7z25 0/1 ContainerCreating 0 66m
gpu-operator-569d9c8cb-r5d6x 0/1 ContainerCreating 0 70m
NVIDIAのドキュメントの出力結果と比べると、nvidia-*とのpodが存在していない。
(5) サンプルのGPUアプリを起動
$ cat sample-gpu.yaml
apiVersion: v1
kind: Pod
metadata:
name: cuda-vectoradd
spec:
restartPolicy: OnFailure
containers:
- name: cuda-vectoradd
image: "nvidia/samples:vectoradd-cuda11.2.1"
resources:
limits:
nvidia.com/gpu: 1
$ kubectl apply -f sample-gpu.yaml
pod/cuda-vectoradd created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
cuda-vectoradd 0/1 Pending 0 28s
nginx-deployment-6595874d85-88x8d 1/1 Running 0 10m
nginx-deployment-6595874d85-nctbg 1/1 Running 0 10m
nginx-deployment-6595874d85-v7x4n 1/1 Running 0 10m
上記の通り、サンプルのgpu podであるcuda-vectoraddがPendingのままである。
因みに、nginxのdeploymentで作成したpodについては、次の通りRunning状態であった。(replicas=3とした)
$ kubectl apply -f nginx-deployment.yaml
deployment.apps/nginx-deployment created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
nginx-deployment-6595874d85-88x8d 1/1 Running 0 2m55s
nginx-deployment-6595874d85-nctbg 1/1 Running 0 2m55s
nginx-deployment-6595874d85-v7x4n 1/1 Running 0 2m55s
まとめ
ここまで説明した通り、kubernetesをkubeadmでインストールして、クラスターを構築できるところまできたが、当初目標としていたGPUクラスターは構築できていない。 gpu deploymentしても、podがPendingのままで、Running状態にならない!
解決したら、修正した記事を再度アップする。