はじめに
先週、NVIDIA TITAN Vをヤフオクで入手した。その実力次第を知るため、姫野ベンチをOpenACCでコンパイル・実行した。対象のGPUは初代TITAN、GTX 1080、RTX A4000、および今回入手したTITAN Vで、各単精度、倍精度での実行結果を測定した。
情報源
- 本家のダウンロードページ ここから、C, static allocate versionのMサイズをダウンロードしたが、結局は、項番3のページのものを使った。
- HPC WORLDのアーカイブ このページは、旧ソフテックから公開されていた内容のアーカイブ版。サンプルプログラムを用いて、OpenACCの説明がされている良いページ。
- 姫野ベンチマークへの適用(C) このページで公開されている「himenobench_kernels.c」を使った。
測定に使ったプログラム
購入したNVIDIA TITAN V。これをHP Z620の初代TITANと入れ替えた。

測定に使ったプログラムは「情報源」の項番3からダウンロードした。ダウンロードしたものは、既にOpenACCのディレクティブが挿入されている単精度計算だったので、floatをdoubleに置き換えて倍精度版として使用した。
コンパイルする際に使用するGPUに応じ、「-ta=nvidia,cc35」のcc35の部分をnvaccelinfoの出力結果に応じて、適切に選択。
結果
各GPU毎で、単精度、倍精度の実行結果(MFLOPS measuredの数値)をグラフ化したものを添付する。
結果は、自分の実行環境での結果(動作しているサーバ環境も異なる)であることに注意。
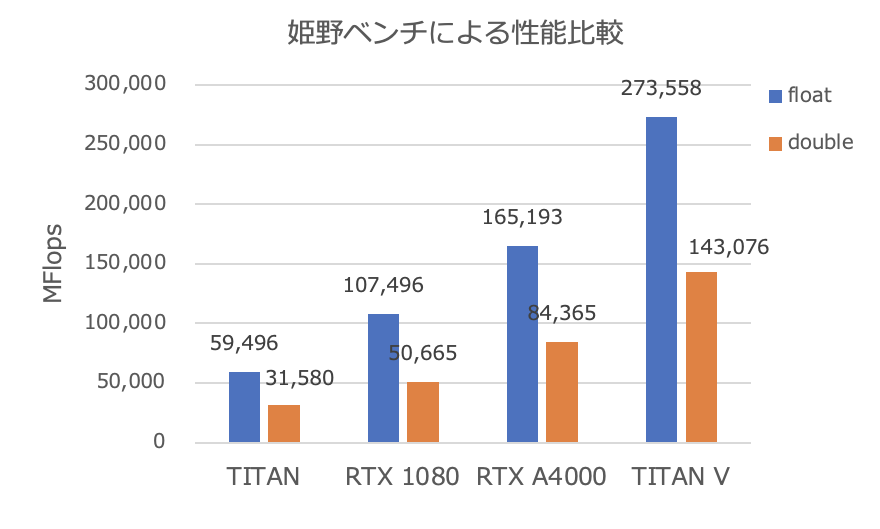
自分の予想では、倍精度演算は、TITAN Vが圧勝で、単精度演算は、RTX A4000が良い線行くのではないかと思っていたが、TITAN Vが(RTX A4000に対し)倍精度・単精度ともに、大きく水を開けた結果であった。
今度は、Deep Learning学習を例に実行速度を比較してみたい。