はじめに
Deep Learningを少し勉強してきて、自分の興味ある分野で使ってみることができなかと思い試した。自分は天文が好きで中でも恒星の進化・元素の生成、それから銀河形成・進化に興味を持っている。比較的簡単にできそうな銀河の形状分類にチャレンジした。
情報源
- astroNN 形状分類を行うための銀河イメージおよび教師データを探して、見つけたページ。このページのDATASETSにあるGalaxy10 DECals Datasetを使うことにした。
このデータは、toy datasetだとこのページに書かれていた。Toy datasetとの記載があったのは、Galaxy10 SDSS Datasetの方でした。 何れにせよ、このデータを作成するために多くの先人の努力に感謝。 - 努力のガリレオ CNNの実装について、以前Udemyで学んだコードをベースとしようかとも考えたが、最終的にコードの骨格はこのページを参考にさせてもらった。
- VGG16 CNNのアーキテクチャとしては、歴史を辿る意味でも先ずはVGG16モデルを試すことにし、このページを参考にした。
- ResNet 次のモデルとしは、ResNetを使うことにし、このページを参考にした。
上記の参照ページから分かる通り、CNNのモデルについては流用しているので、自分が実際に手を動かしたのは、データの作成に関わる部分である。 自身の環境としては、Ubuntu+GPU上にPytorchが動くJupyterLabのsingularityイメージを使っている。
Dataset作成
今回のチャレンジで一番大変だった部分。これまでは出来合いのデータであるMNISTを使ってCNNの勉強をしたが、自分でイメージデータからDataset、DataLoaderを作成するまでに苦労した。
具体的には、Datasetを作成するサブクラスを作成し、訓練用とテスト用にtorch.utils.data.rondom_splitを使ってdatasetを分割すると、訓練用とテスト用に各々別のtransformsを使う方法が分からなかった。
今回使ったGalaxy10 DECals Datasetのデータは、10のクラス毎にイメージデータがまとまっているものであった。そのため、イメージデータの順番をランダムにシャッフルしたものから、訓練用とテスト用に分けるようにした。
# Galaxy10のデータを読み込み、シャッフルしたのち、訓練用とテスト用に分ける
import h5py
import numpy as np
import random
with h5py.File('../20221214_galaxy/galaxy10/Galaxy10_DECals.h5', 'r') as F:
images = np.array(F['images'])
labels = np.array(F['ans'])
galaxys = images.shape[0] # 銀河データの数
train_size = int(0.8 * galaxys)
test_size = galaxys - train_size
train_indices = []
test_indices = []
for i in range(galaxys):
idx = random.randint(0, galaxys-1)
if i < train_size:
train_indices.append(idx)
else:
test_indices.append(idx)
import torch
from torch.utils.data import Dataset
from torch.utils.data import DataLoader
import torchvision
import torchvision.transforms as transforms
from typing import List, Tuple
from PIL import Image
class GalaDataset(Dataset):
def __init__(self, images:np.ndarray, labels:np.ndarray, indices:list, transforms) -> None:
super().__init__()
self.images = images # 読み込んだ全ての銀河イメージ
self.labels = labels
self.indices = indices # 訓練用/テスト用を切り分けるため、読み込んだ銀河のインデックスを格納
self.transforms = transforms
def __getitem__(self, index: int) -> Tuple[torch.Tensor, torch.Tensor]:
idx = self.indices[index] # 読み込んだ銀河データのインデックスを得る
image = self.images[idx]
image = Image.fromarray(image)
label = self.labels[idx]
# apply transforms
if self.transforms is not None:
image = self.transforms(image)
return (image, label)
def __len__(self) -> int:
return len(self.indices) # 訓練用/テスト用でサイズは別なことに注意
上記のGalaDatasetというDatasetのサブクラスにたどり着くまでに少し苦労した。このGalaDatasetで訓練用とテスト用のインスタンスを作成すれば、イメージデータのコピーすることなく2つのデータセットができる。
train_transforms = transforms.Compose([
transforms.CenterCrop(224),
# transforms.RandomRotation(degrees=[-30, 30]),
# transforms.RandomHorizontalFlip(p=0.3),
transforms.ToTensor(),
])
test_transforms = transforms.Compose([
transforms.CenterCrop(224),
transforms.ToTensor(),
])
# 訓練用とテスト用のDatasetを上記で定義したクラスから作成
train_dataset = GalaDataset(images=images, labels=labels,
indices=train_indices,transforms=train_transforms)
test_dataset = GalaDataset(images=images, labels=labels,
indices=test_indices,transforms=test_transforms)
Datasetを訓練用とテスト用で分けたかった理由は、訓練用には回転や左右反転等(コメントアウトしてある部分)のtransformsを施したかった。
# DataLoaderを作成
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(test_dataset, batch_size=batch_size, shuffle=True)
以上でDataLoaderができたので、ここからはモデルの作成と学習・評価となる。
VGG16モデル
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
class Net(nn.Module):
def __init__(self):
super().__init__()
self.conv01 = nn.Conv2d(3, 64, 3)
self.conv02 = nn.Conv2d(64, 64, 3)
self.pool1 = nn.MaxPool2d(2, 2)
self.conv03 = nn.Conv2d(64, 128, 3)
self.conv04 = nn.Conv2d(128, 128, 3)
self.pool2 = nn.MaxPool2d(2, 2)
self.conv05 = nn.Conv2d(128, 256, 3)
self.conv06 = nn.Conv2d(256, 256, 3)
self.conv07 = nn.Conv2d(256, 256, 3)
self.pool3 = nn.MaxPool2d(2, 2)
self.conv08 = nn.Conv2d(256, 512, 3)
self.conv09 = nn.Conv2d(512, 512, 3)
self.conv10 = nn.Conv2d(512, 512, 3)
self.pool4 = nn.MaxPool2d(2, 2)
self.conv11 = nn.Conv2d(512, 512, 3)
self.conv12 = nn.Conv2d(512, 512, 3)
self.conv13 = nn.Conv2d(512, 512, 3)
self.pool5 = nn.MaxPool2d(2, 2)
self.avepool1 = nn.AdaptiveAvgPool2d((7, 7))
self.fc1 = nn.Linear(512 * 7 * 7, 4096)
self.fc2 = nn.Linear(4096, 4096)
self.fc3 = nn.Linear(4096, 10)
self.dropout1 = nn.Dropout(0.5)
self.dropout2 = nn.Dropout(0.5)
def forward(self, x):
x = F.relu(self.conv01(x))
x = F.relu(self.conv02(x))
x = self.pool1(x)
x = F.relu(self.conv03(x))
x = F.relu(self.conv04(x))
x = self.pool2(x)
x = F.relu(self.conv05(x))
x = F.relu(self.conv06(x))
x = F.relu(self.conv07(x))
x = self.pool3(x)
x = F.relu(self.conv08(x))
x = F.relu(self.conv09(x))
x = F.relu(self.conv10(x))
x = self.pool4(x)
x = F.relu(self.conv11(x))
x = F.relu(self.conv12(x))
x = F.relu(self.conv13(x))
x = self.pool5(x)
x = self.avepool1(x)
# 行列をベクトルに変換
x = x.view(-1, 512 * 7 * 7)
x = F.relu(self.fc1(x))
x = self.dropout1(x)
x = F.relu(self.fc2(x))
x = self.dropout2(x)
x = self.fc3(x)
return x
全結合層の最後の部分、参照元は5クラス分類だったが、今回は10クラス分類なので、10に変更。
device = 'cuda' if torch.cuda.is_available() else 'cpu'
model = Net().to(device)
訓練と評価関数群
# 損失関数の設定
criterion = nn.CrossEntropyLoss()
# 最適化手法を設定
optimizer = optim.Adam(model.parameters())
学習関数
def train_epoch(model, optimizer, criterion, dataloader, device):
train_loss = 0
model.train()
for i, (images, labels) in enumerate(dataloader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_loss = train_loss / len(train_loader.dataset)
return train_loss
推論関数
def inference(model, optimizer, criterion, dataloader, device):
model.eval()
test_loss=0
with torch.no_grad():
for i, (images, labels) in enumerate(dataloader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
test_loss = test_loss / len(test_loader.dataset)
return test_loss
指定エポック数を実行する関数
def run(num_epochs, optimizer, criterion, device):
train_loss_list = []
test_loss_list = []
for epoch in range(num_epochs):
train_loss = train_epoch(model, optimizer, criterion, train_loader, device)
test_loss = inference(model, optimizer, criterion, test_loader, device)
print(f'Epoch [{epoch+1}], train_Loss : {train_loss:.4f}, test_Loss : {test_loss:.4f}')
train_loss_list.append(train_loss)
test_loss_list.append(test_loss)
return train_loss_list, test_loss_list
実行部分
# 訓練時間を測定:開始
import time
import datetime
dt_now = datetime.datetime.now()
print("*** Started the Timer at {} ***".format(dt_now))
start_time = time.time() # 実行時間計測開始
train_loss_list, test_loss_list = run(30, optimizer, criterion, device)
# 訓練時間測定:終了
lapse_time = time.time() - start_time
print("-" * 80)
print("実行時間 {:8.1f}秒".format(lapse_time))
print("-" * 80)
dt_now = datetime.datetime.now()
print("*** Stopped the Timer at {} ***".format(dt_now))
グラフ化
import matplotlib.pyplot as plt
num_epochs=30
fig, ax = plt.subplots(figsize=(8, 6), dpi=100)
ax.plot(range(num_epochs), train_loss_list, c='b', label='train loss')
ax.plot(range(num_epochs), test_loss_list, c='r', label='test loss')
ax.set_xlabel('epoch', fontsize='20')
ax.set_ylabel('loss', fontsize='20')
ax.set_title('training and test loss', fontsize='20')
ax.grid()
ax.legend(fontsize='25')
plt.show()
得られたグラフイメージを次のとおり。
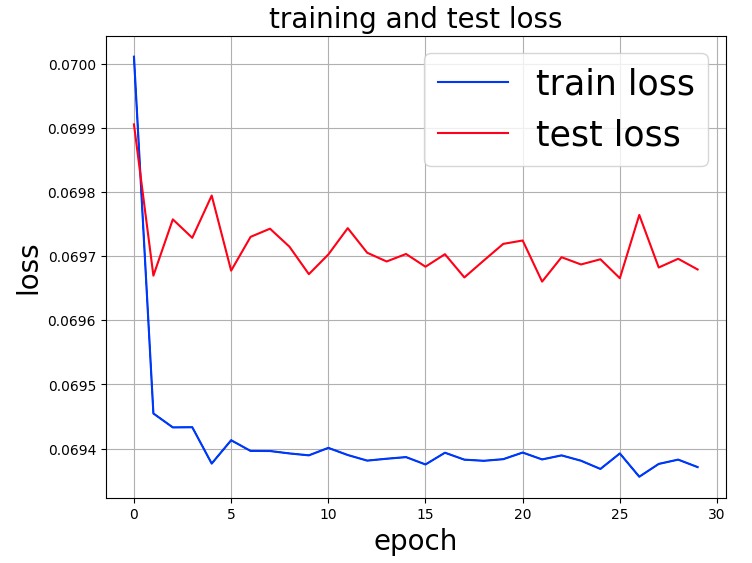
epochを重ねても、train loss、test loss共に改善しない。どこに原因があるのだろうか?
少し記事が長くなったので、今回はここまで。 次回は、先の疑問に関して、試してみたことをまとめる予定。