はじめに
昨年末のこの記事で、銀河形状の分類をCNN(VGG16, ResNet)を行ったことを述べた。今回は、銀河形状分類をTransformerを用いたVison Transformer(ViT)で行う。
情報源
教師データとしては、前回同様、AstroNNのGalaxy10 DECals Datasetを使用する。
- Vision Transformerモデルのファインチューニングを試す Vision Transformerによる分類、ファインチューニングについての解説記事。自分はこのページを参考にして、ViTモデルおよびファインチューニングを行った。
- Pytorch - torchvision で使える Transform まとめ 汎化性能を高めるため(過学習を抑えるため)にData Augmentationを行ったが、pytorchではtransformで行う。その説明記事。
Vision Transformerモデル
DataLoaderを作成するまでは、VGG16の場合と同じ。
準備
# Training settings
epochs = 30
lr = 3e-5
gamma = 0.7
seed = 42
device = 'cuda' if torch.cuda.is_available() else 'cpu'
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.optim.lr_scheduler import StepLR
from linformer import Linformer
from vit_pytorch.efficient import ViT
import timm
Efficient Attentionとパラメータ設定
efficient_transformer = Linformer(
dim=128,
seq_len=49+1, # 7x7 patches + 1 cls-token
depth=12,
heads=8,
k=64
)
# num_classesの変更が必要。
# 変更せずに10クラス分類をすると、以下のようなエラーとなる。
# エラーの発生場所は、to(device)のタイミングで発生するが、そこに原因はない。
# RuntimeError: CUDA error: device-side assert triggered
# CUDA kernel errors might be asynchronously reported at some other API call,so the stacktrace below might be incorrect.
# For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
model = ViT(
dim=128,
image_size=224,
patch_size=32,
num_classes=10,
transformer=efficient_transformer,
channels=3,
).to(device)
ロス関数、Optimizerの設定
# loss function
criterion = nn.CrossEntropyLoss()
# optimizer
optimizer = optim.Adam(model.parameters(), lr=lr)
# scheduler
scheduler = StepLR(optimizer, step_size=1, gamma=gamma)
訓練
学習部分は、VGG16の場合と基本は同じだが、accuracyも求めるようにした。
accuracy計算関数
def cal_acc(outputs, labels):
p_arg = torch.argmax(outputs, dim = 1)
return torch.sum(labels == p_arg)
この関数の戻り値はtorch.Tensorであることに注意。
学習関数
train_acc(あるエポックにおける、訓練データでのaccuracy)も返すように変更。
def train_epoch(model, optimizer, criterion, dataloader, device):
train_loss = 0
train_acc = 0
model.train()
for i, (images, labels) in enumerate(dataloader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
train_loss += loss.item()
train_acc += cal_acc(outputs, labels).item()
train_loss = train_loss / len(dataloader.dataset)
train_acc = train_acc / len(dataloader.dataset)
return train_loss, train_acc
推論関数
test_acc(あるエポックにおける、テストデータでのaccuracy)も返すように変更。
def inference(model, optimizer, criterion, dataloader, device):
model.eval()
test_loss=0
test_acc = 0
with torch.no_grad():
for i, (images, labels) in enumerate(dataloader):
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
test_loss += loss.item()
test_acc += cal_acc(outputs, labels).item()
test_loss = test_loss / len(dataloader.dataset)
test_acc = test_acc / len(dataloader.dataset)
return test_loss, test_acc
指定のエポックを実行する関数
訓練/テストデータによるaccuracyとlossのリストを返すように変更。
def run(num_epochs, optimizer, criterion, device):
train_loss_list = []
test_loss_list = []
train_acc_list = []
test_acc_list = []
for epoch in range(num_epochs):
train_loss, train_acc = train_epoch(model, optimizer, criterion, train_loader, device)
test_loss, test_acc = inference(model, optimizer, criterion, test_loader, device)
print(f'Epoch [{epoch+1}], train_Loss : {train_loss:.4f}, test_Loss : {test_loss:.4f}, train_acc : {train_acc:.4f}, test_acc : {test_acc:.4f}')
train_loss_list.append(train_loss)
test_loss_list.append(test_loss)
train_acc_list.append(train_acc)
test_acc_list.append(test_acc)
return train_loss_list, test_loss_list, train_acc_list, test_acc_list
呼び出し部
# 訓練時間を測定:開始
import time
import datetime
dt_now = datetime.datetime.now()
print("*** Started the Timer at {} ***".format(dt_now))
start_time = time.time() # 実行時間計測開始
train_loss_list, test_loss_list, train_acc_list, test_acc_list = run(epochs, optimizer, criterion, device)
# 訓練時間測定:終了
lapse_time = time.time() - start_time
print("-" * 80)
print("実行時間 {:8.1f}秒".format(lapse_time))
print("-" * 80)
dt_now = datetime.datetime.now()
print("*** Stopped the Timer at {} ***".format(dt_now))
accuracyとlossのグラフ表示
import matplotlib.pyplot as plt
# Plot loss & accuracy
num_epochs=30
fig = plt.figure(figsize=(12,6), dpi=100)
ax1 = fig.add_subplot(1, 2, 2) # error in right side
ax2 = fig.add_subplot(1, 2, 1)
ax1.plot(range(num_epochs), train_loss_list, c='b', label='train loss')
ax1.plot(range(num_epochs), test_loss_list, c='r', label='test loss')
ax1.set_xlabel('epoch', fontsize='14')
ax1.set_ylabel('loss', fontsize='14')
ax1.set_title('training and test loss', fontsize='18')
ax1.grid()
ax1.legend(fontsize='18')
ax2.plot(range(num_epochs), train_acc_list, c='b', label='train accuracy')
ax2.plot(range(num_epochs), test_acc_list, c='r', label='test accuracy')
ax2.set_xlabel('epoch', fontsize='14')
ax2.set_ylabel('accuracy', fontsize='14')
ax2.set_title('training and test accuracy', fontsize='18')
ax2.grid()
ax2.legend(fontsize='18')
plt.show()
実行結果
実行結果のグラフは次のとおり。
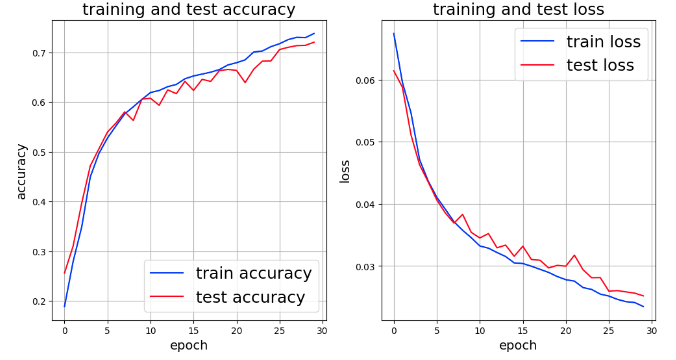
Epochを伸ばすと、多少改善しそうであるが、accuracyとlossは共にResNetのそれより下回っているようだ。
この記事では、lossのグラフ化のみであったので、ViTの結果との比較のためResNetでもaccuracyも求めるようにした結果が次のグラフである。
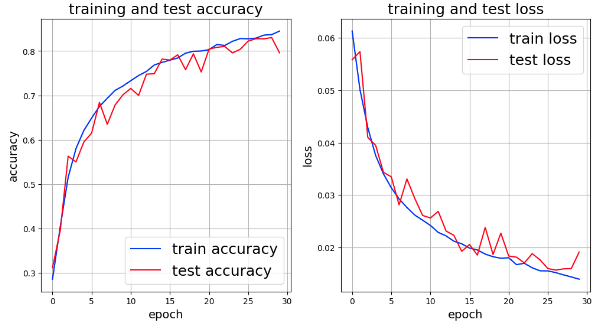
次回は、既に学習済みのモデルを使ったファインチューニングを行う予定。