はじめに
この記事で、Transformerの画像処理への適応のVision Transformer (ViT)を用いて、銀河形状分類を行った。今回は、ViTのモデルとして既に学習済みのモデルを使って同じ分類を行った。
ViTをファインチューニング
前回の記事の「Efficient Attentionとパラメータ設定」節の部分を以下に置き換える。
事前学習されたモデルをロード
model = timm.create_model('vit_small_patch16_224', pretrained=True, num_classes=10)
model.to(device)
たったこれだけ。
前回の記事で「ロス関数、Optimizerの設定」節より以降の部分は変更なし。
実行結果
事前学習モデルでファインチューニングした実行結果は次のとおり。
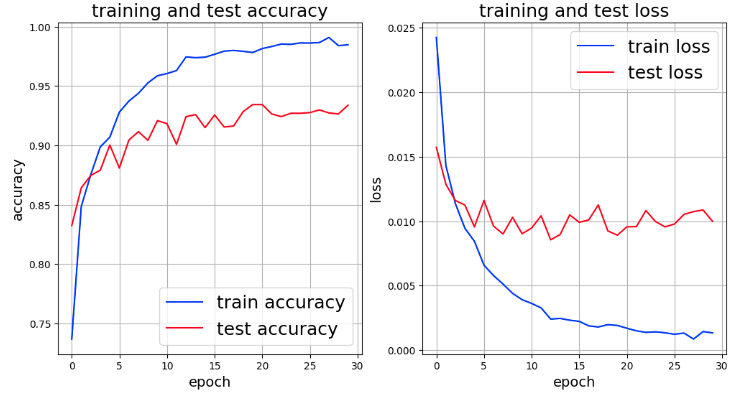
上記のグラフから、ResNetでのaccuracyとlossより良い値を示しているが、過学習していることが分かる。そこで、学習用画像にtransformsでaugmentationを適用してみたい。
画像の一部をランダムに消去、回転角度を少し強める
transoformsを次のとおりに変更。
train_transforms = transforms.Compose([
transforms.CenterCrop(224),
transforms.RandomRotation(degrees=[-45, 45]),
transforms.RandomHorizontalFlip(p=0.3),
transforms.ToTensor(),
transforms.RandomErasing(scale=(0.1, 0.2), ratio=(0.8, 1.2), p=0.3),
])
その実行結果は次のとおり。
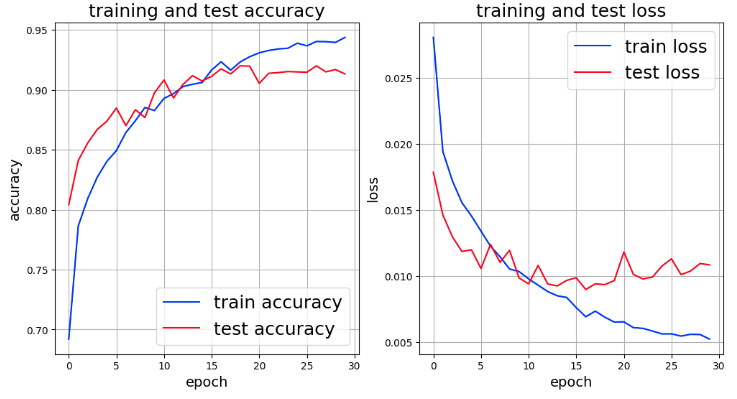
過学習については、改善は見られるもの、15エポックを超えた辺りから過学習しているようだ。
以下の通り、RandomErasingのscaleを変更し、削除する領域を少しだけ増加した。
train_transforms = transforms.Compose([
transforms.CenterCrop(224),
transforms.RandomRotation(degrees=[-45, 45]),
transforms.RandomHorizontalFlip(p=0.3),
transforms.ToTensor(),
transforms.RandomErasing(scale=(0.1, 0.3), ratio=(0.8, 1.2), p=0.3),
])
結果のグラフは次のとおり。過学習は、かなり改善したようだが、データにaugmentationを施すとaccuracyとloss共に悪化しているようにも見える。
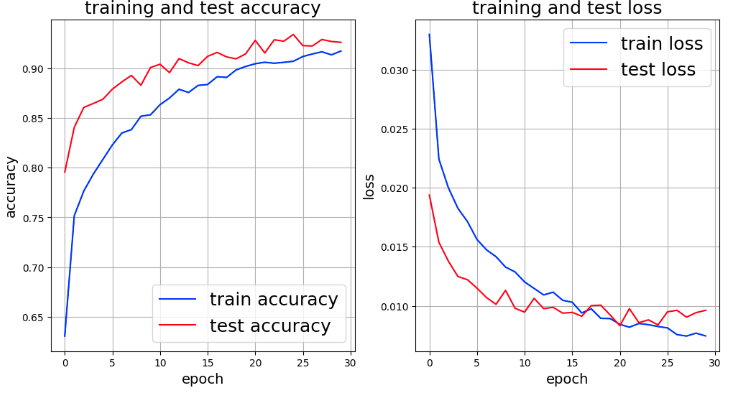
今後、学習データのaugmentationの効果をもう少し分析的に明らかにしたい。
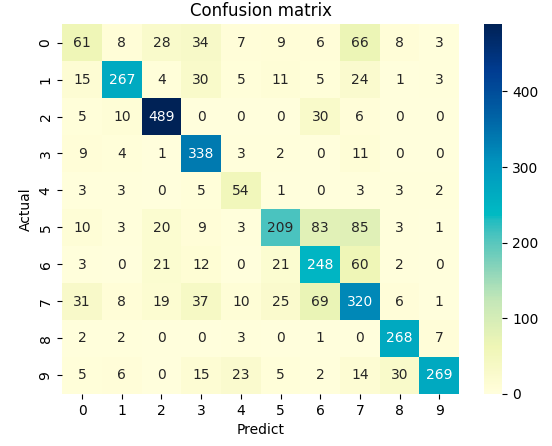
その際は、次のような混同行列の結果を見ながら分析してみる。