モチベーション
JupyterLabのnotebookの格納先をNFSとしている自宅の環境で、NFSサーバをRaspberryPiもしくはHP Z240とした際の性能測定していて、学習ループ(epochを重ねている状態)では、NBの格納先がNFSサーバ、ローカルでも大差ないことが分かった。
そこで、学習を高速化することにチャレンジしたので、その経過/結果をここにまとめた。
情報源
- PyTorchでの学習・推論を高速化するコツ集 この記事の3つを試した。
環境
次のシステム構成図で、saiseiでJupyterLabを動かし、europeに格納しているNoteBookをNFSマウントしている。
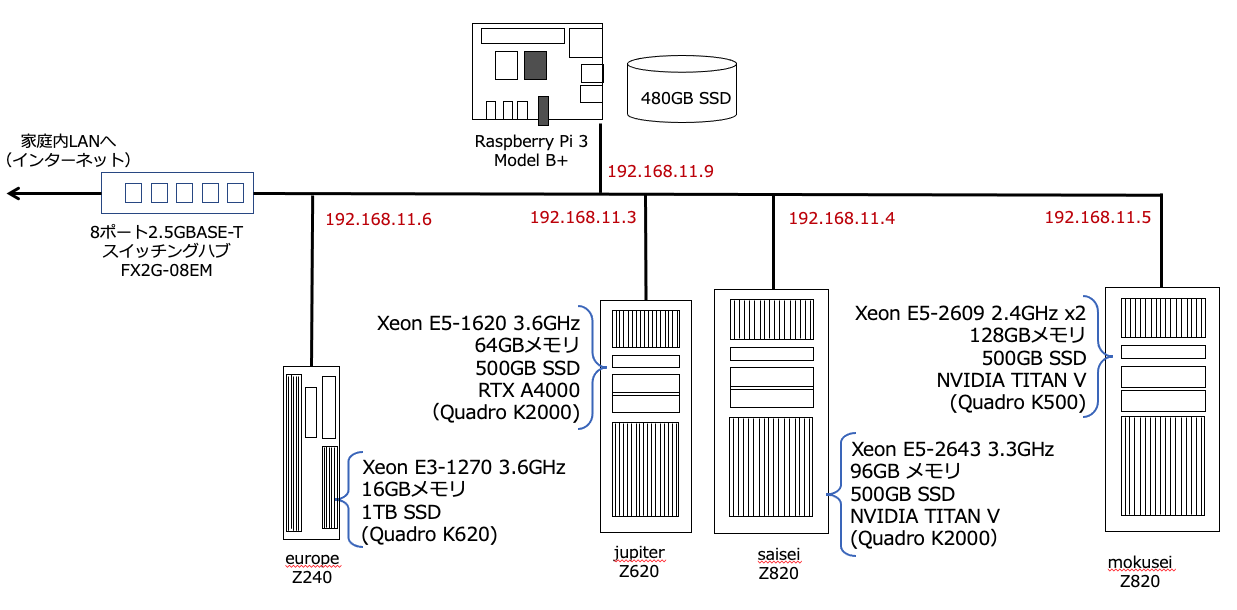
高速化する前の元のプログラムは、この記事で紹介したvgg16のモデルを使った銀河形状分類のプログラムを使った。学習率は$lr=0.00001$とした。
高速化への取り組み
num_workers
DataLoaderを作成する際のパラメータに"num_workers=2"を追加。
# DataLoaderを作成
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True, num_workers=2)
pin_memory
同じく、DataLoaderを作成するパラメータに"pin_memory=True"を追加。
# DataLoaderを作成
batch_size = 32
train_loader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
valid_loader = DataLoader(valid_dataset, batch_size=batch_size, shuffle=True, num_workers=2, pin_memory=True)
AMP(Automatic Mixed Precision)を導入
学習、推論のループ(1epochのループ)で、AMPを利用し、次のように修正した。
学習ループ
def train_epoch(model, optimizer, criterion, dataloader, device):
train_loss = 0
train_acc = 0
model.train()
scaler = torch.cuda.amp.GradScaler() # add for amp
for i, (images, labels) in enumerate(dataloader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
with torch.cuda.amp.autocast(): # add for amp
outputs = model(images)
loss = criterion(outputs, labels)
scaler.scale(loss).backward() # add for amp
scaler.step(optimizer) # add for amp
scaler.update() # add for amp
# loss.backward()
# optimizer.step()
train_loss += loss.item()
train_acc += cal_acc(outputs, labels).item()
train_loss = train_loss / len(dataloader.dataset)
train_acc = train_acc / len(dataloader.dataset)
return train_loss, train_acc
推論ループ
def inference(model, optimizer, criterion, dataloader, device):
model.eval()
valid_loss=0
valid_acc = 0
scaler = torch.cuda.amp.GradScaler() # add for amp
with torch.no_grad():
for i, (images, labels) in enumerate(dataloader):
images, labels = images.to(device), labels.to(device)
with torch.cuda.amp.autocast(): # add for amp
outputs = model(images)
loss = criterion(outputs, labels)
valid_loss += loss.item()
valid_acc += cal_acc(outputs, labels).item()
valid_loss = valid_loss / len(dataloader.dataset)
valid_acc = valid_acc / len(dataloader.dataset)
return valid_loss, valid_acc
結果
jupiter(GPU:RTX A4000)での実行結果は、次の表のとおり。
| 変更要素(累積的) | 実行時間(秒) | 実行時間比 |
|---|---|---|
| オリジナル | 3,342 | 1.0 |
| +num_worker | 3,198 | 0.96 |
| +num_worker+pin_memory | 3,073 | 0.92 |
| +num_worker+pin_memory+AMP | 2,163 | 0.65 |
AMP(Automatic Mixed Precision)が非常に効果高い結果である。
同じ条件で、saisei(GPU:TITAN V)で実行した結果は、次の通り。
| 変更要素(累積的) | 実行時間(秒) | 実行時間比 |
|---|---|---|
| オリジナル | 2,670 | 1.0 |
| +num_worker | 2,440 | 0.91 |
| +num_worker+pin_memory | 2,339 | 0.88 |
| +num_worker+pin_memory+AMP | 1,558 | 0.58 |
同じく、AMPの効果が高い。
今後は、上記3つの高速化を施したものを標準的に使うことにする。