はじめに
Horovod in Dockerを試すで、自分の環境(オンプレミス)で、Docker環境下でHorovodを使えるようになった。次にやるべきことは、一台のサーバで動作する学習コードをHorovodを使った分散学習に適用するように変更することだ!手始めに比較的簡単なCNNコードをHorovodを使って分散学習できるように変更したので、以下記事にまとめる。
情報源
- 本家のドキュメント - PytorchでHorovodを使うため、訓練コードを変更する手順を説明したドキュメント。
元になったCNN訓練コード
Horovod対応するベースとしたCNN訓練コード(pythonコード)は、以前Udemyで学習したコードを使うことにした。
Udemyのタイトルは「AIによる画像分類を学ぼう!【Pytorch+Golabo】CNNの基礎からTransformerの応用まで」
上記教材のSection2では、cifar10データを使った画像分類をCNNで実装している。以下で、Horovodで変更すべき箇所のみ抜粋する。他の部分について、各々UdemyやWebで調べて欲しい。
DataLoader
# DataLoaderの設定
batch_size = 64
train_loader = DataLoader(cifar10_train, batch_size=batch_size, shuffle=True)
test_loader = DataLoader(cifar10_test, batch_size=batch_size, shuffle=False)
誤差関数、最適化アルゴリズム
from torch import optim
# 交差エントロピー誤差関数
loss_fnc = nn.CrossEntropyLoss()
# 最適化アルゴリズム
optimizer = optim.Adam(net.parameters())
Horovod対応のための変更
初期化部分
オリジナルのCNN訓練コードの冒頭に、次のような初期化部分を追加する。
import torch
import horovod.torch as hvd
# Initialize Horovod
hvd.init()
# Pin GPU to be used to process local rank (one GPU per porcess)
if torch.cuda.is_available():
torch.cuda.set_device(hvd.local_rank())
DataLoader
DataLoader部分は、次のように変更した。 shuffle=Trueを元のコードと同じようにDataLoader()の引数にするとエラーとなる。samplerとshuffleは両立しない(排他的)関係とのエラーだったと記憶している。
# DataLoaderの設定
batch_size = 64
#train_loader = DataLoader(cifar10_train, batch_size=batch_size, shuffle=True)
#test_loader = DataLoader(cifar10_test, batch_size=batch_size, shuffle=False)
# Partition dataset among workers using Distributed Sampler
train_sampler = torch.utils.data.distributed.DistributedSampler(
cifar10_train, num_replicas=hvd.size(), rank=hvd.rank(), shuffle=True)
train_loader = DataLoader(cifar10_train, batch_size=batch_size,
sampler=train_sampler)
test_sampler = torch.utils.data.distributed.DistributedSampler(
cifar10_test, num_replicas=hvd.size(), rank=hvd.rank(), shuffle=False)
test_loader = DataLoader(cifar10_train, batch_size=batch_size,
sampler=test_sampler)
誤差関数、最適化アルゴリズム
誤差関数、最適化アルゴリズムの部分は、horovod用にラップするため次のように変更する。
from torch import optim
# 交差エントロピー誤差関数
loss_fnc = nn.CrossEntropyLoss()
# 最適化アルゴリズム
optimizer = optim.Adam(net.parameters())
# Add Horovod Distributed Optimizer
optimizer = hvd.DistributedOptimizer(optimizer,
named_parameters=net.named_parameters())
# Broadcast parameters & optimizer state from rank 0 to all other processes.
hvd.broadcast_parameters(net.state_dict(), root_rank=0)
hvd.broadcast_optimizer_state(optimizer, root_rank=0)
修正コードをHorovod in Dockerで使う
Primaryサーバ
修正したpythonコードはNFS領域(/mnt/nfs/sample、自分はNFS領域を使ったが、ローカルのディレクトリで問題なし)に格納した。その上でhorovodを起動する際に次のようにマウント(-v /mnt/nfs/sample:/root/sampleの部分)して、コンテナで使えるようにした。
$ sudo docker run -it --gpus all --net=host \
-v /mnt/nfs2/ssh:/root/.ssh \
-v /mnt/nfs/sample:/root/sample \
horovod/horovod:latest
コンテナ内では、1台目、2台目、3台目と各々次のように起動した。時間計測のためtimeを使っている。
# time horovodrun -np 1 -H localhost:1 python cifar10.py
# time horovodrun -np 2 -H192.168.11.3:1,192.168.11.5:1 -p 12345 python cifar10.py
# time horovodrun -np 3 -H192.168.11.3:1,192.168.11.5:1,192.168.11.6:1 -p 12345 python cifar10.py
Secondaryサーバ
$ sudo docker run -it --gpus all --net=host \
-v /mnt/nfs2/ssh:/root/.ssh \
-v /mnt/nfs/sample:/root/sample \
horovod/horovod:latest \
bash -c "/usr/sbin/sshd -p 12345; sleep infinity"
実行結果
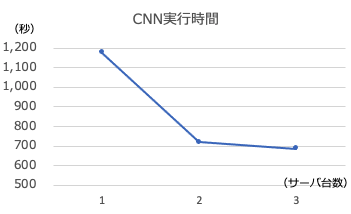
timeで計測したreal時間は次の通り。
| 使用サーバ数(台数) | 実行時間(秒) |
|---|---|
| 1 | 1176 |
| 2 | 770 |
| 3 | 687 |
まとめ
上記の通り元のコードに対し、変更すべき箇所は、追加部分、修正部分に大別され、ほんの数行追加/修正すれば、分散学習に使えることが分かった。
-
追加
- 初期化:hvd.init()
- GPUとプロセス紐付け:torch.cuda.set_device(hvd.local_rank())
-
修正
- DataLoaderで、Distributed samplerを使って、データセットを分割
- Distributed Optimizerでoptimizerをwrap
- parametersとoptimizer statsをrank=0から送信
今後もう少し、Horovodで使うためのコード修正について学んでいきたい。