モチベーション
昨日のこの投稿の通り、複数ノード上で動作しているDockerコンテナでOpenMPIを使ったプログラムを動かせるようになった。OpenMPIによってどのぐらい性能が向上するのかを調べたくなったので、ベンチマークすることにした。 実は、今回も少し苦労した点があり、その部分が他の方の参考になれば嬉しい。
情報源
- 姫野ベンチマーク 姫野ベンチマークの本家のページ。
- Horovod with MPI 今回苦労した点についてもこのページに答えがあった。
- OpenMPI(v3.1.3)で複数ノードに渡る並列化ができなくて困っていた問題の解決法 多分自分と同じ現象及び解決策が出ている。ただし、このページは物理マシンでの解決方法。
ダウンロード、1台のマシンで実行
ダウンロード
ダウンロードページから「C+MPI, static allocate version」をダウンロードする。lzhで圧縮してあるので、jlha-utilsパッケージをインストールして、ダウンロードしたlzhファイルを解凍する。
$ sudo apt install jlha-utils
$ lha x cc_himenobmtxp_mpi.lzh
解凍から、1台のマシンで実行するまでは、ダウンロードページの「How to use」の説明の通り。
自分は、解凍したファイルを/ext/nfs/athena++/himeno配下にコピーして、そこで作業した。昨日説明した通り、この領域は、他のノードからNFSマウントされている。
これ以降はdockerコンテナでの作業である。paramset.shには実行権を付与した。
# pwd
/workdir/himeno
# mv param.h param.h.org
# ./paramset.sh M 1 1 2
# cp Makefile.sample Makefile
# ls -l
total 44
-rw-rw-r-- 1 1000 1000 251 Feb 22 12:24 Makefile
-rw-rw-r-- 1 1000 1000 251 Feb 22 12:20 Makefile.sample
-rw-rw-r-- 1 1000 1000 4414 Feb 22 12:19 cc_himenobmtxp_mpi.lzh
-rw-rw-r-- 1 1000 1000 13099 Feb 22 12:20 himenoBMTxps.c
-rw-rw-r-- 1 root root 196 Feb 22 12:23 param.h
-rw-rw-r-- 1 1000 1000 202 Feb 22 12:20 param.h.org
-rwxrwxr-x 1 1000 1000 2079 Feb 22 12:20 paramset.sh
# make
makeでwarningが出力されるが、bmtというa.outができるので、1台のマシンで実行する。
# mpirun -np 2 ./bmt
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Sequential version array size
mimax = 129 mjmax = 129 mkmax = 257
Parallel version array size
mimax = 129 mjmax = 129 mkmax = 131
imax = 128 jmax = 128 kmax =129
I-decomp = 1 J-decomp = 1 K-decomp =2
Start rehearsal measurement process.
Measure the performance in 3 times.
MFLOPS: 9847.792258 time(s): 0.041767 1.667103e-03
Now, start the actual measurement process.
The loop will be excuted in 4309 times
This will take about one minute.
Wait for a while
cpu : 64.531007 sec.
Loop executed for 4309 times
Gosa : 1.978532e-04
MFLOPS measured : 9155.072245
Score based on Pentium III 600MHz : 110.515116
ここまで来れば、昨日の経験もあるので、複数ノードでbenchmarkを動かすことは簡単だと思った。
同時実行のプロセスを増やす
ここまでで、2プロセスを1台のマシンで実行させることができたので、次は4プロセスを実行させることにした。そのために次を実行した。パラメータの意味は、ダウンロードページを参照されたい。
# cat hosts.txt
europe
ganymede
jupiter
# ./paramset.sh M 1 2 2
# make
# mpirun --hostfile hosts.txt -mca plm_rsh_args "-p 12345" -np 4 $(pwd)/bmt
結果は次のとおり。
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Invalid number of PE
Please check partitioning pattern or number of PE
この時のPEがどんな値なのか(期待値は1x2x2=4)を調べるため、エラーを出している部分に、以下を追加してみた。
printf("PE=%d\n",npe);
そしてmakeした時に気づいた! param.hが更新されても、himenoBMTxps.cはコンパイルされず(himenoBMTxps.oは更新されず)bmtが作られていた。次のようようにすれば上手くいく。
# ./paramset.sh M 1 2 2
# make clean
# make
# mpirun --hostfile hosts.txt -mca plm_rsh_args "-p 12345" -np 4 $(pwd)/bmt
複数ノードでの実行
プロセス数を2、4、8、16、32、64と変化させてbenchmarkを実行することにした。計算サイズはLにする。
最初にプロセス数を中間の8として実行した。事前に「./maramset.sh L 2 2 2」を実行してparam.hを更新し、その後「make clean」、「make」を実行しているが、この部分の記述は省略する。また、この時のmyhostsは、前出のhosts.txtと同じである。
# mpirun -np 8 --hostfile myhosts -mca plm_rsh_args "-p 12345" -oversubscribe $(pwd)/bmt
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
[ganymede][[22394,1],4][../../../../../../opal/mca/btl/tcp/btl_tcp_endpoint.c:625:mca_btl_tcp_endpoint_recv_connect_ack] received unexpected process identifier [[22394,1],7]
「received unexpected process identifier」で検索してヒットしたのが、情報源3.のページである。
このページの解決法「実行時のオプションに--mca btl_tcp_if_include eth0を追加」を読んで、情報源2.を思い出し、次のようにして解決できた。
# mpirun -np 8 --hostfile myhosts -mca plm_rsh_args "-p 12345" -mca btl_tcp_if_exclude lo,docker0 $(pwd)/bmt
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Authorization required, but no authorization protocol specified
Sequential version array size
mimax = 257 mjmax = 257 mkmax = 513
Parallel version array size
mimax = 131 mjmax = 131 mkmax = 259
imax = 129 jmax = 129 kmax =257
I-decomp = 2 J-decomp = 2 K-decomp =2
Start rehearsal measurement process.
Measure the performance in 3 times.
MFLOPS: 19912.780454 time(s): 0.168541 8.841949e-04
Now, start the actual measurement process.
The loop will be excuted in 1067 times
This will take about one minute.
Wait for a while
(以下省略)
今回も、Horovod in Dockerの経験が役に立った。
性能測定
以下の計測では、5台のマシンを使って測定した。この時のhostfileは次のとおり。
# cat myhosts
europe
jupiter
ganymede
saisei
mokusei
slot指定なし
| np | MFLOPS |
|---|---|
| 2 | 9,177 |
| 4 | 11,267 |
| 8 | 20,501 |
| 16 | 20,111 |
| 32 | 20,607 |
| 64 | 8,411 |
np=8でサチっているのは、おかしいのではないかと考えた。以下の表(各マシンのスペックの抜粋)から分かるとおり、5台のマシンの物理コア数(# of CPU x # of core)の合計は26なので、16がピークでサチると考えていた。
| jupiter | ganymede | saisei | mokusei | europe | |
|---|---|---|---|---|---|
| CPU | Xeon(R) CPU E5-1620 @ 3.60GHz | Xeon(R) CPU E5-2620 @ 2.00GHz | Xeon(R) CPU E5-2643 @ 3.30GHz | Xeon(R) CPU E5-2609 @ 2.40GHz | eon(R) CPU E3-1270 v5 @ 3.60GHz |
| # of CPU | 1 | 1 | 1 | 2 | 1 |
| # of core | 4 | 6 | 4 | 4 | 4 |
slot指定あり
hostfileに各マシンの物理コア数をslotとして記載してみることにした。
# cat myhosts
europe slots=4
jupiter slots=4
ganymede slots=6
saisei slots=4
mokusei slots=8
実行結果は次のとおり。想定していた傾向の結果である。
| np | MFLOPS |
|---|---|
| 2 | 9,171 |
| 4 | 11,234 |
| 8 | 20,413 |
| 16 | 29,589 |
| 32 | 23,018 |
| 64 | 9,216 |
測定結果をグラフにすると次のとおり。
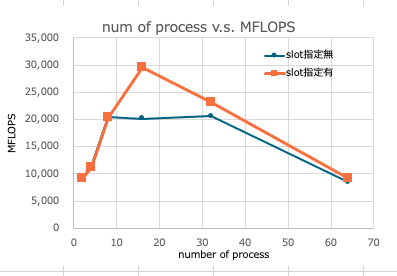
まとめ
物理コア数までは、並列処理するプロセス数が増えれば性能も向上するものと考えていたが、そのような結果を得ることができた。slot指定の有無によりプロセス数のピークに差が出ることの理由は分からない。
今回計算サイズは「L」として測定したが、計算サイズの違いがどのように影響するのかは、今後調べてみたい。