はじめに
先月投稿したこの記事までで、OpenMPIをDockerコンテナに組み込み、マルチノードで並列計算できることは確認できた。この投稿では、上記で作成したDockerコンテナを使って、Athena++のチュートリアル4「3次元磁気流体シミュレーションと並列計算」をマルチノードで実行させる。
情報源
- Athena Tutorial 今回実行するのは「4. Running 3D MHD with OpenMP and MPI」である。
- 上記の日本語のページ 富田 賢吾先生が管理されているページ。
- H5Pset_fapl_mpio was not declared in this scope コンパイルエラーの原因調査のため、検索しヒットしたページ。parallel HDF5ライブラリが必要との記述があった。
- [h5fortran-mpi](https://github.com/geospace-code/h5fortran-mpi) parallel HDF5 libraryで検索してヒットしたページ。ubuntuではlibhdf5-mpi-devパッケージとの記述があった。
実行環境
Dockerfile
このチュートリアルを実行するためのDockerfileは次のとおり。
# JupyterLabが使えるDockerイメージ作成用のDockefileを元にして、
# athena++開発・実行で使えるDockerコンテナを作成する。
# ubuntu 22.04の最新版をベースとする。
FROM ubuntu:jammy-20240111
# Set bash as the default shell
ENV SHELL=/bin/bash
# Build with some basic utilities
RUN apt update && apt install -y \
build-essential \
python3-pip apt-utils vim \
git git-lfs \
curl unzip wget gnuplot \
openmpi-bin libopenmpi-dev \
openssh-client openssh-server \
libhdf5-dev libhdf5-openmpi-dev
# alias python='python3'
RUN ln -s /usr/bin/python3 /usr/bin/python
# install python package to need
RUN pip install -U pip setuptools \
&& pip install numpy scipy h5py mpmath
# The following stuff is derived for horovod in docker.
# Allow OpenSSH to talk to containers without asking for confirmation
RUN mkdir -p /var/run/sshd
RUN cat /etc/ssh/ssh_config | grep -v StrictHostKeyChecking > /etc/ssh/ssh_config.new && \
echo " StrictHostKeyChecking no" >> /etc/ssh/ssh_config.new && \
mv /etc/ssh/ssh_config.new /etc/ssh/ssh_config
# --allow-run-as-root
ENV OMPI_ALLOW_RUN_AS_ROOT=1
ENV OMPI_ALLOW_RUN_AS_ROOT_CONFIRM=1
# Set hdf5 path
ENV CPATH="/usr/include/hdf5/openmpi/"
# Create a working directory
WORKDIR /workdir
# command prompt
CMD ["/bin/bash"]
最終的には、上記のDockerfileから作成したコンテナを使うと、今回のチュートリアルは実行できた。このDockerfileを得るために行なった試行錯誤を以下に述べる。ポイントはMPI環境でHDF5を使えるようにすることであった。
HDF5を使うためのコンテナ作成するまでのエラーの記録
先ずは、次のようなコンフィギュレーションを行う。
# python configure.py --prob blast -b --flux hlld -mpi -hdf5
Your Athena++ distribution has now been configured with the following options:
Problem generator: blast
Coordinate system: cartesian
Equation of state: adiabatic
Riemann solver: hlld
Magnetic fields: ON
Number of scalars: 0
Number of chemical species: 0
Special relativity: OFF
General relativity: OFF
Radiative Transfer: OFF
Implicit Radiation: OFF
Cosmic Ray Transport: OFF
Frame transformations: OFF
Self-Gravity: OFF
Super-Time-Stepping: OFF
Chemistry: OFF
KIDA rates: OFF
ChemRadiation: OFF
chem_ode_solver: OFF
Debug flags: OFF
Code coverage flags: OFF
Linker flags: -lhdf5
Floating-point precision: double
Number of ghost cells: 2
MPI parallelism: ON
OpenMP parallelism: OFF
FFT: OFF
HDF5 output: ON
HDF5 precision: single
Compiler: g++
Compilation command: mpicxx -O3 -std=c++11
# make clean
rm -rf obj/*
rm -rf bin/athena
rm -rf *.gcov
hdf5.h: No such file or directory
# make
mpicxx -O3 -std=c++11 -c src/globals.cpp -o obj/globals.o
mpicxx -O3 -std=c++11 -c src/main.cpp -o obj/main.o
In file included from src/main.cpp:46:
src/outputs/outputs.hpp:22:10: fatal error: hdf5.h: No such file or directory
22 | #include <hdf5.h>
| ^~~~~~~~
compilation terminated.
make: *** [Makefile:119: obj/main.o] Error 1
上記のエラーの対応のため、Dockerfileにlibhdf5-devをインストールするよう追加した。ただ、これだけでは、エラーは解決せず、Dockerfileにexport CPATH="/usr/include/hdf5/serial/“を追加した。
その上で、改めてmakeした。
#ifdef MPI_PARALLEL
# make
mpicxx -O3 -std=c++11 -c src/globals.cpp -o obj/globals.o
・・・
・・・
mpicxx -O3 -std=c++11 -c src/inputs/hdf5_reader.cpp -o obj/hdf5_reader.o
src/inputs/hdf5_reader.cpp: In function 'void HDF5ReadRealArray(const char*, const char*, int, const int*, const int*, int, const int*, const int*, AthenaArray<double>&, bool, bool)':
src/inputs/hdf5_reader.cpp:94:7: error: 'H5Pset_fapl_mpio' was not declared in this scope; did you mean 'H5Pset_fapl_stdio'?
94 | H5Pset_fapl_mpio(property_list_file, MPI_COMM_WORLD, MPI_INFO_NULL);
| ^~~~~~~~~~~~~~~~
| H5Pset_fapl_stdio
src/inputs/hdf5_reader.cpp:109:7: error: 'H5Pset_dxpl_mpio' was not declared in this scope; did you mean 'H5Pset_fapl_stdio'?
109 | H5Pset_dxpl_mpio(property_list_transfer, H5FD_MPIO_COLLECTIVE);
| ^~~~~~~~~~~~~~~~
| H5Pset_fapl_stdio
make: *** [Makefile:119: obj/hdf5_reader.o] Error 1
上記のエラー箇所は、ソースコード上 #ifdef MPI_PARALLELの箇所であったので、OpenMPIを使う並列計算の場合には、hdf5関連のモジュールが必要なのでは無いかと調べた。
情報源の3.と4.とで当たりをつけ、Dockerfileにlibhdf5-openmpi-devをインストールするようした。それに伴い上記で追加したCPATH設定をCPATH="/usr/include/hdf5/openmpi” に変更した。
リンクエラー
再びmakeすると、コンパイルして最後のリンク時に次のようなエラーとなった。
/usr/bin/ld: cannot find -lhdf5: No such file or directory
collect2: error: ld returned 1 exit status
make: *** [Makefile:114: bin/athena] Error 1
ライブラリ格納場所である/usr/lib/x86_64-linux-gnu配下を調べてみると、必要なライブラリは、hdf5_openmpiと当たりを付け、コンフィギュレーションの結果、生成されたMakefileの「-lhdf5」を「-lhdf5_openmpi」に変更した。
以上の結果、本節の最初に示したDockerfileを得た。
シミュレーションの実行
パラメータファイルの編集
前回のチュートリアルと同じように、コンテナ内の作業用のディレクトリ「t4」にパラメータファイルと実行形式をコピーする。パラメータファイルは、athena/inputs/mhd/athinput.blastをコピーした。
# pwd
/workdir/kenji/t4
# ls -l
-rwxr-xr-x 1 root root 3613256 Mar 2 04:11 athena
-rw-r--r-- 1 root root 2193 Mar 2 08:12 athinput.blast
今回、並列処理で時間測定するので、敢えて多少時間が掛かるようにメッシュを2倍に設定することとした。athinput.blastの変更点は次のとおり。
10c10
< file_type = hdf5 # HDF5 data dump
---
> file_type = vtk # VTK data dump
13d12
< ghost_zones = true # enables ghost zone output
24c23
< nx1 = 128 # Number of zones in X1-direction
---
> nx1 = 64 # Number of zones in X1-direction
30c29
< nx2 = 128 # Number of zones in X2-direction
---
> nx2 = 64 # Number of zones in X2-direction
36c35
< nx3 = 128 # Number of zones in X3-direction
---
> nx3 = 64 # Number of zones in X3-direction
42,47c41
< #num_threads = 1 # Number of OpenMP threads per process
<
< <meshblock>
< nx1 = 32 # Number of zones per MeshBlock in X1-direction
< nx2 = 32 # Number of zones per MeshBlock in X2-direction
< nx3 = 32 # Number of zones per MeshBlock in X3-direction
---
> num_threads = 1 # Number of OpenMP threads per process
シミュレーション時間の計測
次のようなシェルコマンドを作成し、プロセス数(np)を2、4、8を実行し、logに記録されるcpu timeを比較する。
# cat mpi_run
mpirun -np $1 --hostfile myhosts \
-mca plm_rsh_args "-p 12345" \
-mca btl_tcp_if_exclude lo,docker0 \
-oversubscribe $(pwd)/athena \
-i $2 > log
# cat myhosts
europe slots=4
jupiter slots=4
ganymede slots=6
# mpi_run 2 athinput.blast
# mpi_run 4 athinput.blast
# mpi_run 8 athinput.blast
計測結果
logに記録されたcpu timeは次のとおりであった。
| プロセス数(np) | cpu time(秒) |
|---|---|
| 2 | 878 |
| 4 | 520 |
| 8 | 408 |
グラフにすると次のとおり。
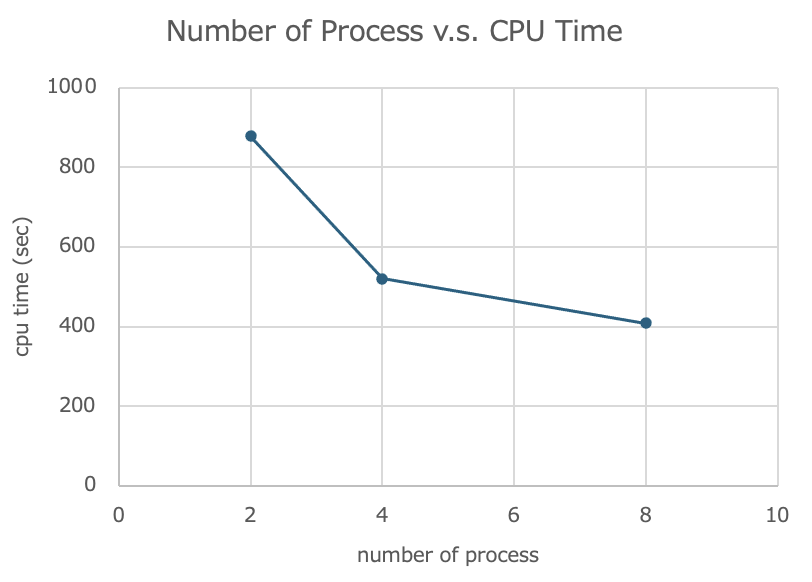
今後について
8プロセス同時に処理すると、2プロセスの約半分の時間でシミュレーションが実行できるとの計測結果を得た。
このチュートリアルについては、シミュレーション結果を可視化する部分が残っているので、そちらについても実行していく。
更に、情報源2.の富田先生のページには、追加課題として、「Rayleigh-Taylor不安定性」のシミュレーションを試す課題が載っているので、それについても実行してみたい。