はじめに
OpenMPI実行ノードの順番を決めるhostfileを変更して、姫野ベンチマークでOpenMPIの性能を再測定したことを、この記事として投稿した。投稿後、改めて考えてみて、CPU、クロックの性能から自分が判断するのではなく、客観的な数値で判断することにした。
そこで今回、個々のワークステーション(ノード)の性能を測定し、その結果に従ってhostfileの順序を決め、再々測定することにした。
各ワークステーションの性能測定
性能測定には、MPIバージョンと条件を揃えるため、C、static allocate versionの計算サイズはLで行うことにした。
結果は、次のとおりであった。この投稿のワークステーションの一覧に今回の測定結果を追加した。
| jupiter | ganymede | saisei | mokusei | europe | |
|---|---|---|---|---|---|
| CPU | Xeon(R) CPU E5-1620 @ 3.60GHz | Xeon(R) CPU E5-2620 @ 2.00GHz | Xeon(R) CPU E5-2643 @ 3.30GHz | Xeon(R) CPU E5-2609 @ 2.40GHz | eon(R) CPU E3-1270 v5 @ 3.60GHz |
| # of CPU | 1 | 1 | 1 | 2 | 1 |
| # of core | 4 | 6 | 4 | 4 | 4 |
| MFLOPS | 4,775 | 3,312 | 4,616 | 3,109 | 5,438 |
hostfile
上記の結果から、hostfileは次のように変更した。
# cat myhosts
europe slots=4
jupiter slots=4
saisei slots=4
ganymede slots=6
mokusei slots=8
測定結果
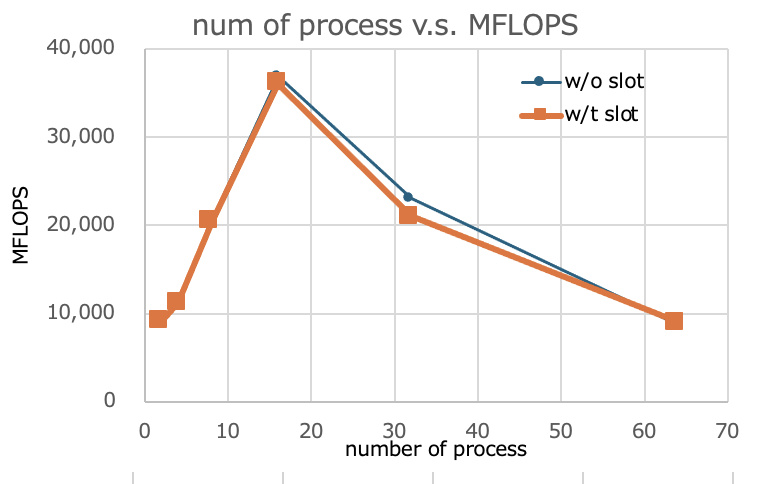
起動プロセス数とslot無し/有りのMFLOPS値は以下の通りの結果であった。
| np | MFLOPS(slot指定なし) | MFLOPS(slot指定あり) |
|---|---|---|
| 2 | 9,186 | 9,179 |
| 4 | 11,294 | 11,260 |
| 8 | 20,411 | 20,433 |
| 16 | 36,907 | 36,056 |
| 32 | 23,041 | 21,068 |
| 64 | 8,734 | 9,040 |
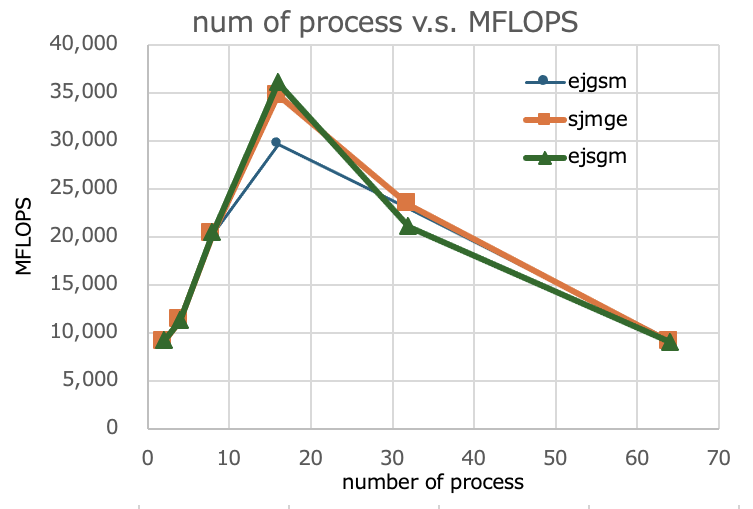
これまで、3回の測定結果のグラフは次のとおり。今回の結果の名称はejsgmとする。
まとめ
前回(3月17日の記事の結果)と比較して、今回の結果は、16プロセス時に数パーセント数値は良くはなっているが、押し並べてみると変わっていないと判断している。
最初(2月23日の記事)の16プロセス時の測定結果について、何らかの理由で正しくなかったのかも分からない。
検証のため再測定(後日追記分)
上記で、この記事の16プロセス時の測定結果が、正しく測定できていないのではないかとの疑いが生じたため、改めて測定してみることにした。
先ずは、hostfileを次のとおり変更した。
# cat myhosts
europe slots=4
jupiter slots=4
ganymede slots=6
saisei slots=4
mokusei slots=8
その後、npを2から64まで変化させて、出力されるMFLOPSを記録した。結果は次のとおり、参考までに、2月23日の値も併記する。
| np | MFLOPS(2月23日記事) | MFLOPS(今回測定) | 前回/今回比 |
|---|---|---|---|
| 2 | 9,171 | 9,170 | 1.000 |
| 4 | 11,234 | 11,200 | 1.000 |
| 8 | 20,413 | 20,437 | 0.999 |
| 16 | 29,589 | 29,660 | 0.998 |
| 32 | 23,018 | 23,179 | 0.993 |
| 64 | 9,216 | 8,290 | 1.112 |
上記の通り、64プロセス時は、少し測定数値にばらつきが出ているが、2から32プロセス時は、非常に良く一致している。したがって、2月23日に投稿した記事のデータは、信頼できると判断する。