はじめに
先日の投稿では、llama-cpp-pythonを使ってローカル環境でELYZA 7Bモデルを動かした。その投稿で「今後について」ChatGPTのように会話できるシステムの構築に挑戦したいと述べた。
今回、ChatGPTのように会話できるシステムをdockerコンテナで構築したので、その内容をここにまとめる。
完成イメージ
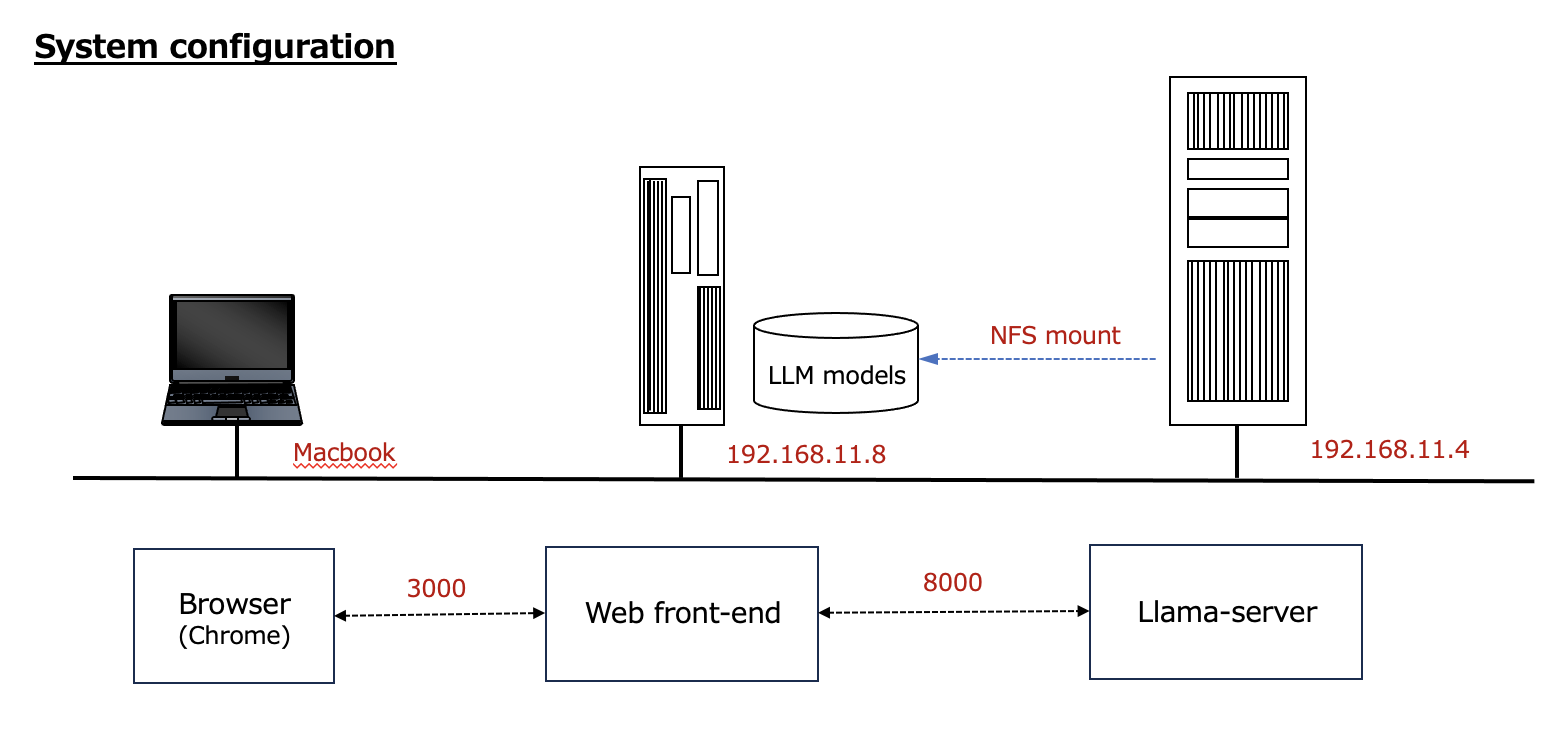
次のような構成でシステムを構築した。
情報源
- llama-cpp-pythonとChatbot UIで複数のローカルLLMをChatGPTライクなWebUIから扱う システム全体像を掴むため役に立った。
- Chatbot UI ChatGPTのAPIをWeb UIで提供するツールのgithubページ。現時点ではv2にアップデートされている。v1はレガシー・ブランチにある。
- Chatbot UI (オープンソースの ChatGPT UI クローン) を Vercel でホストする 上記を実行した内容を日本語で紹介しているページ。
- ELYZA Japanese LLaMA 2 13B を WEB デプロイ 今回の作業の中で、自分が最も参考にしたページ。
- 【WSL2】Ubuntuで最新版のNode.jsをインストールする方法 nodeのバージョンアップの手順を参考にしたページ。
Llama-server
冒頭掲載した「System Configuration」右側の部分である。「ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf」のようなLLMは、中央のサーバのディスクに格納し、そこをNFSマウントしている。
Dockerfile
コンテナ起動時に、モデルを選べるように「-model」オプションはCMDに書き、デフォルトで「ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf」を使うようにしている。
# OpenAI互換サーバを構築する
# llama-cpp-python[server]をインストールしたコンテナ
FROM nvidia/cuda:12.1.1-cudnn8-devel-ubuntu22.04
# Set bash as the default shell
ENV SHELL=/bin/bash
# Build with some basic utilities
RUN apt-get update && apt-get install -y \
build-essential python3-pip apt-utils vim \
git git-lfs curl unzip wget
# alias python='python3'
RUN ln -s /usr/bin/python3 /usr/bin/python
# Install llama-cpp-python[server] with cuBLAS on
RUN CMAKE_ARGS="-DLLAMA_CUBLAS=on" FORCE_CMAKE=1 \
pip install llama-cpp-python[server] --force-reinstall --no-cache-dir
# Create the directory stored models
WORKDIR /models
# Launch llama_cpp server
ENTRYPOINT ["python3", "-m", "llama_cpp.server", "--chat_format", "llama-2", "--n_gpu_layers", "-1", "--host", "0.0.0.0"]
# set default model
CMD ["--model", "ELYZA-japanese-Llama-2-7b-fast-instruct-q4_K_M.gguf"]
コンテナをビルト
上記のDockerfileのあるディレクトリで、次のようにコンテナをビルトする。
$ sudo docker build -t llama-server .
コンテナを起動
作成されたコンテナは次のように起動する。以下で分かる通り、LLMは/mnt/nfs2/modelsに格納されている。実体はNFSマウント先にある。
export MODEL_DIR=/mnt/nfs2/models
export CUDA_VISIBLE_DEVICES=0
sudo docker run --rm --gpus all -v ${MODEL_DIR}:/models -p 8000:8000 llama-server:latest
Webフロントエンド
実はこの部分は少し苦労した。
当初、npmやbrewをインストールした後、情報源2.に従って、Webフロントエンド(Chatbot-ui)を構築しようと考えていた。Dockerコンテナにすることも考えているので、brewのインストールは自分のノウハウではちょっと難しそうに思った。
そこで、情報源4.にしたがって、legacyブランチをcloneして、構築することにした。そこには、Dockerfileもあるので、簡単に構築できるだろうと考えていた。
次のとおり、legacyブランチをcloneした。
$ git clone -b legacy https://github.com/mckaywrigley/chatbot-ui.git
$ cd chatbot-ui
コンテナをビルト
chatbot-uiディレクトリのDockerfileから次のようにコンテナをビルトした。
$ sudo docker build -t chatgpt-ui ./
コンテナを起動
$ sudo docker run --rm -e OPENAI_API_KEY=fake_key -p 3000:3000 chatgpt-ui:latest
Llama-severと接続しない。恐らく、デフォルトの「http://localhost:8000」に接続しようとしていると思われうる。コンテナ起動時に「-e OPENAI_API_HOST=“http://192.168.11.4:8000”」を指定したが上手くいかない。
Webフロントエンド部分のコンテナ化は、一旦諦め、情報源4.の手順に従って、npmから起動するようにした。その手順をいかに説明する。
物理環境上にWebフロントエンドを構築
フロントエンドを構築するために必要なnpmを物理環境にインストールする。
$ sudo apt install npm
その後は、情報源4.に従って、次の通り実行する。
$ npm i
$ npm audit fix --force
$ cp .env.local.example .env.local
.env.localに以下を追加する。
# Chatbot UI
OPENAI_API_HOST="http://192.168.11.4:8000"
OPENAI_API_KEY=fake_key
DEFAULT_SYSTEM_PROMPT="あなたは誠実で優秀な日本人のアシスタントです。"
Webフロントエンドを起動
$ npm run dev
次のようなエラーが出ていた。
/home/kenji/tmp/chatbot-ui/node_modules/next/dist/lib/picocolors.js:134
const { env, stdout } = ((_globalThis = globalThis) == null ? void 0 : _globalThis.process) ?? {};
^
SyntaxError: Unexpected token '?'
提供ソースでエラーが出るとは通常考え難いので、nodeのバージョンが古いのではないかと考え、次の手順を実行した。
エラー対応 〜 nodeの更新
情報源5.に従って、次のようにnodeを最新版に更新した。
$ node -v
v12.22.9
$ sudo npm install -g n
$ sudo n lts
installing : node-v20.12.2
(略)
old : /usr/bin/node
new : /usr/local/bin/node
(略)
$ node -v
v12.22.9
ここで、再起動する。再起動後は、次のとおり最新版に更新されている。
$ node -v
v20.12.2
node更新後、Webフロントエンドを起動
$ npm run dev
ブラウザから接続
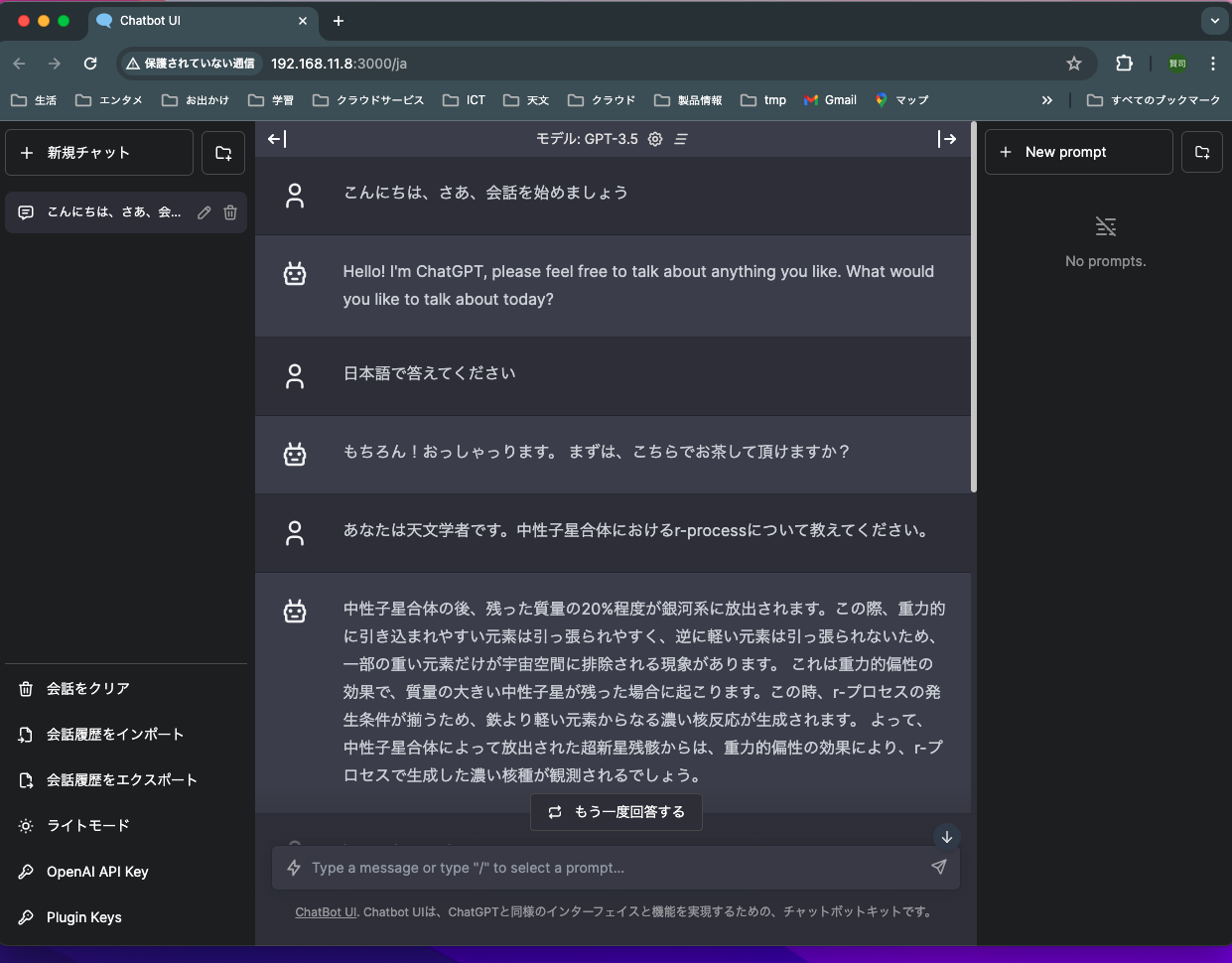
自分は、MacBookProのChromeで、「http://192.168.11.8:3000」とWebフロントエンドに接続すると、LLMとつながって、会話できるようなった。
会話の開始。日本語になった最初の会話が意味不明。
自分がLLMに必ず聞く質問「rプロセスについての説明」を投げてみた。
英語で聞いてみた。
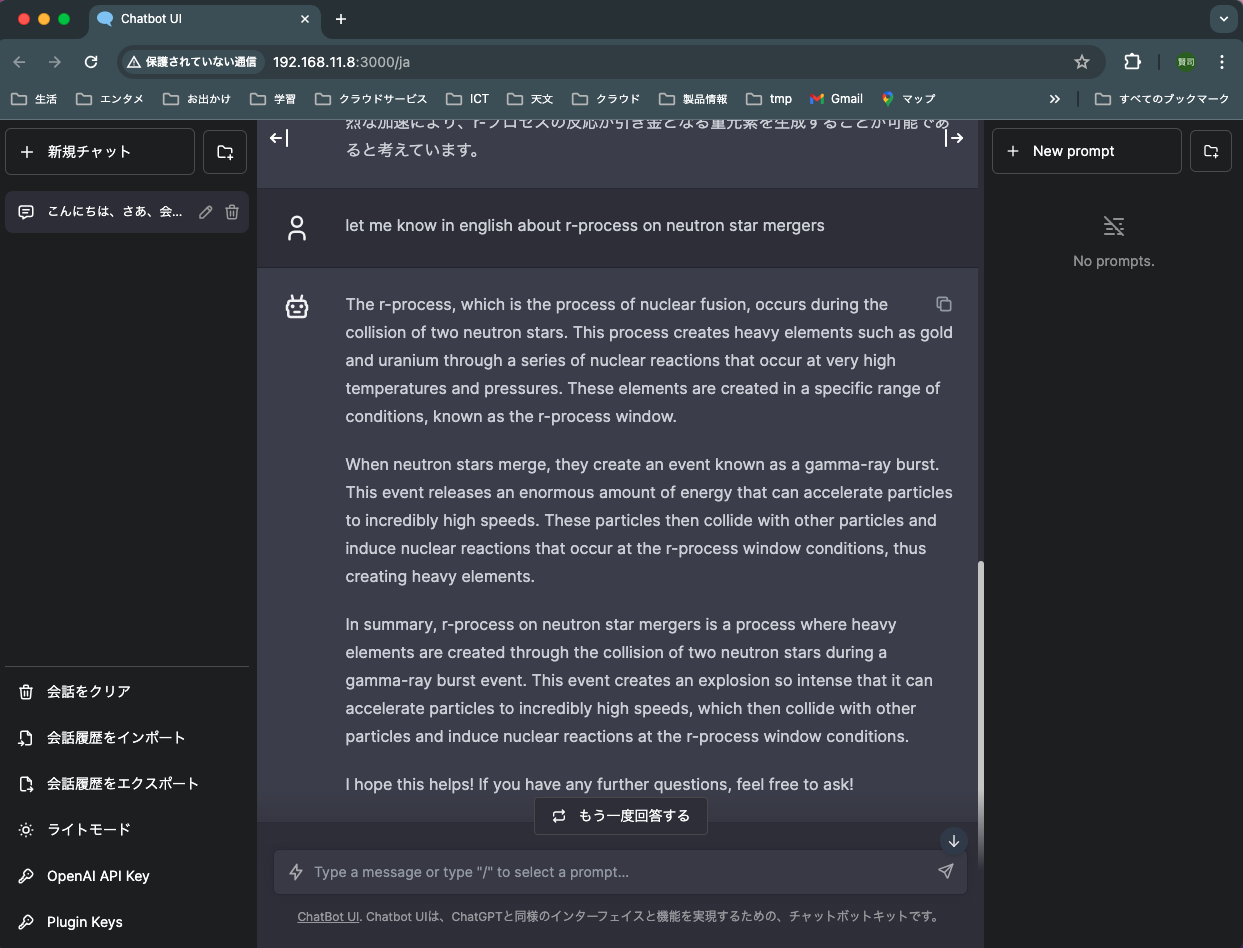
英語の方が詳しくて正確な回答。
まとめ
少しトラブったところもあったが、ローカル環境で、ChatGPTライクなシステムが構築できた。
今後、次のことに挑戦したい。
- Webフロントエンドのコンテナ化、およびv2対応
- LLMの切り替え
- RAGとの連携