モチベーション
この投稿では、Neo4jとLangChainでGraphRAGを試しに構築した。自分は、この本でbedrockを勉強中。せっかくAWSに触れ始めたので、AWS上にGraphRAGを構築することにした。
情報源
- Amazon Bedrock Part 3 この記事を参考に構築した。1年前の記事なので、パッケージ(ライブラリ)構成なども変わっており、コードの一部は変更した。
- Amazon Neptune で GraphRAG アプリケーションを構築するための LlamaIndex のサポートを発表 LlamaIndexを使ってGraphRAGを構築のAWSの紹介記事。
- LlamaIndex + Amazon Neptune GraphRAG やってみた LlamaIndexとNeptuneを使ってGraphRAG構築したQiitaの記事。
NeptuneでGraphRAGを構築
情報源1.を参考に、以下の手順で進めた。
-
Neptuneを起動、設定
-
データベースを作成
-
Neptuneからノートブック(JupyterLab)を作成
-
JupyterLabからコードを入力、動かしてみる
データベース格納するデータは、Cypherで記述された米国映画に関するテキストデータである。
Neptuneの構築
マネジメントコンソールからNeptuneを起動
IAMアカウントのマネジメントコンソールから「Neptune」サービスを選択し、「Amazon Neptuneを起動」でNeptuneを起動する
データベース作成
マネジメントコンソールで、Neptune > データベース > データベースの作成を指定し、次のように設定した。
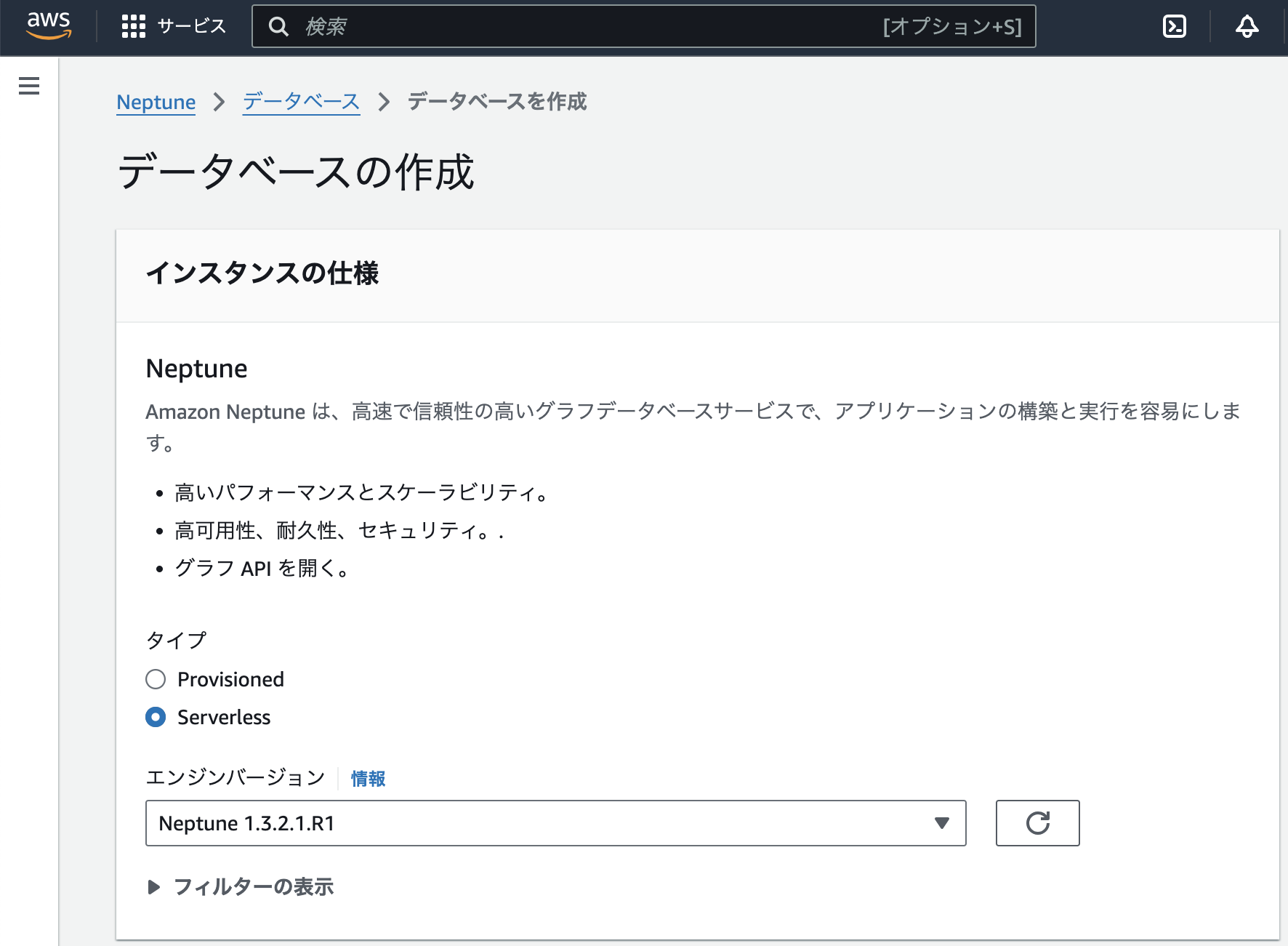
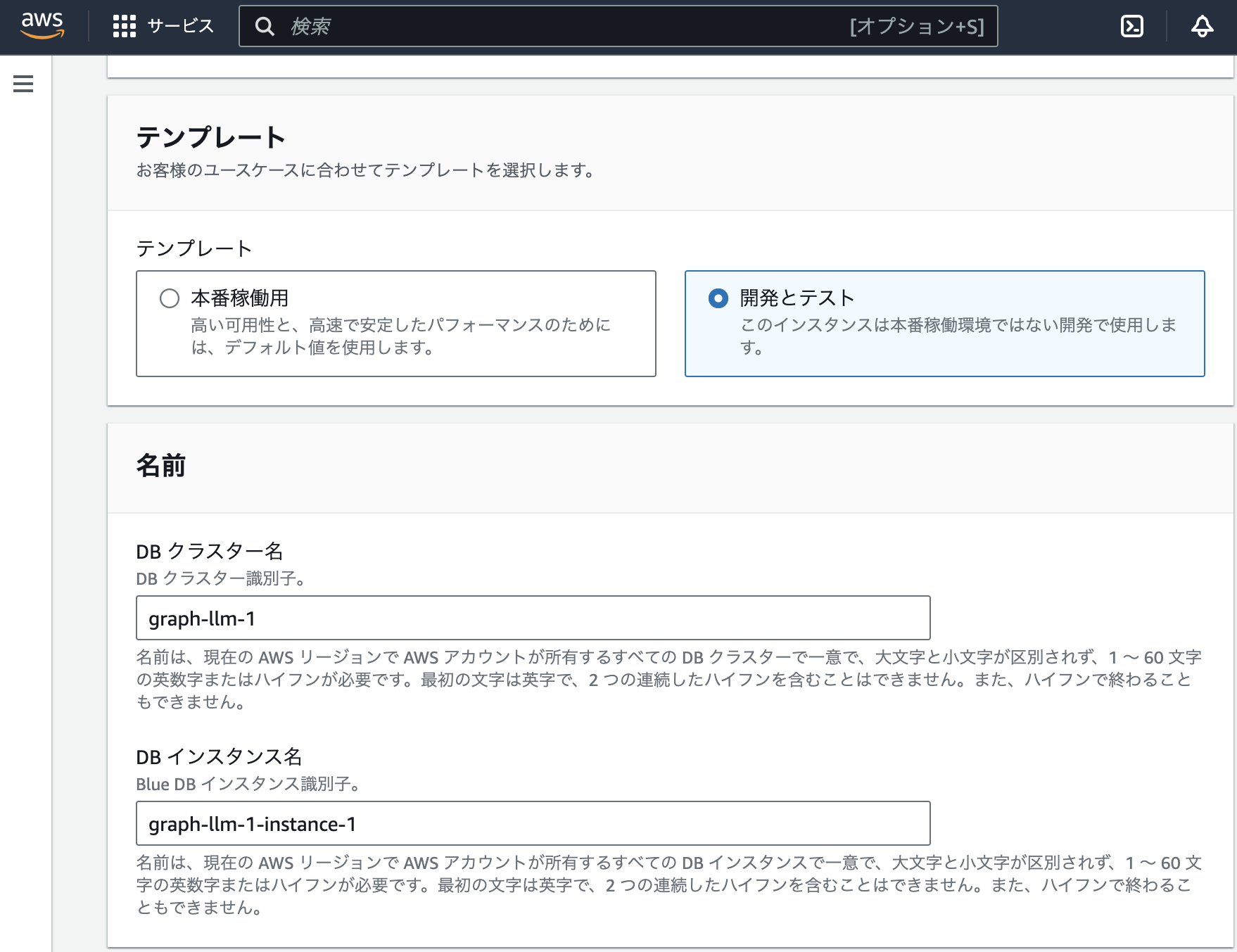
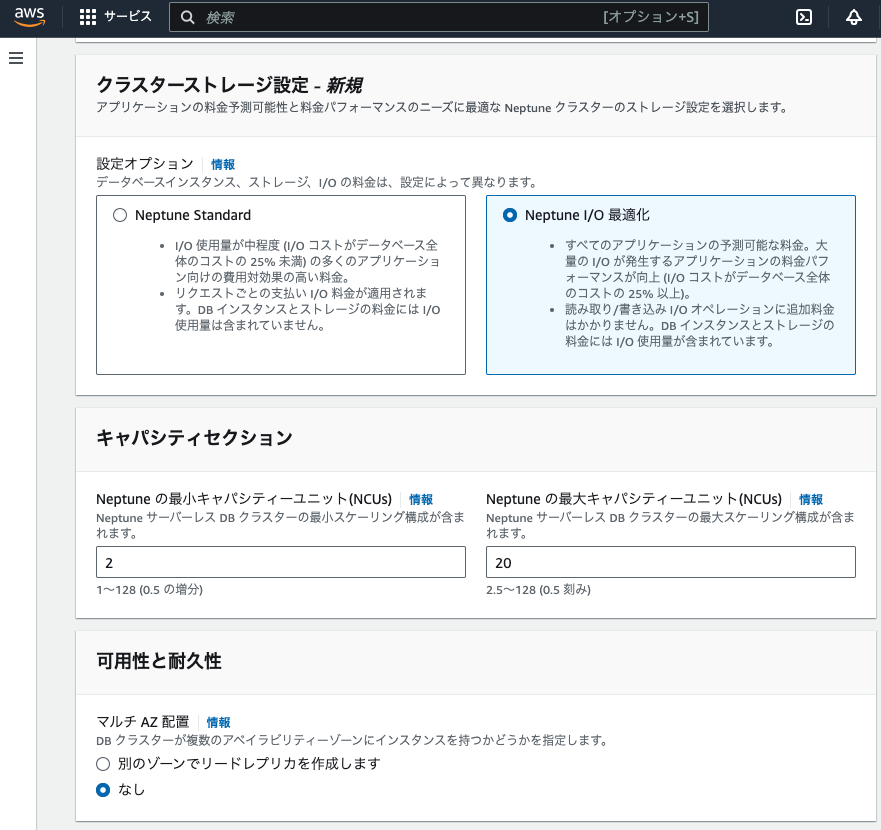
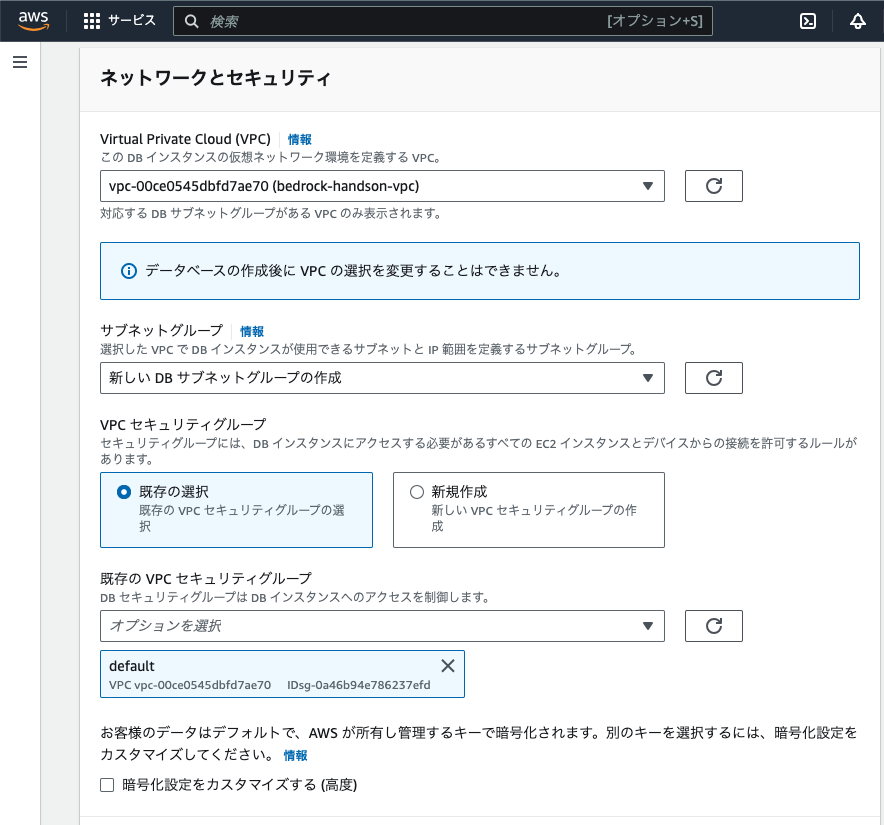
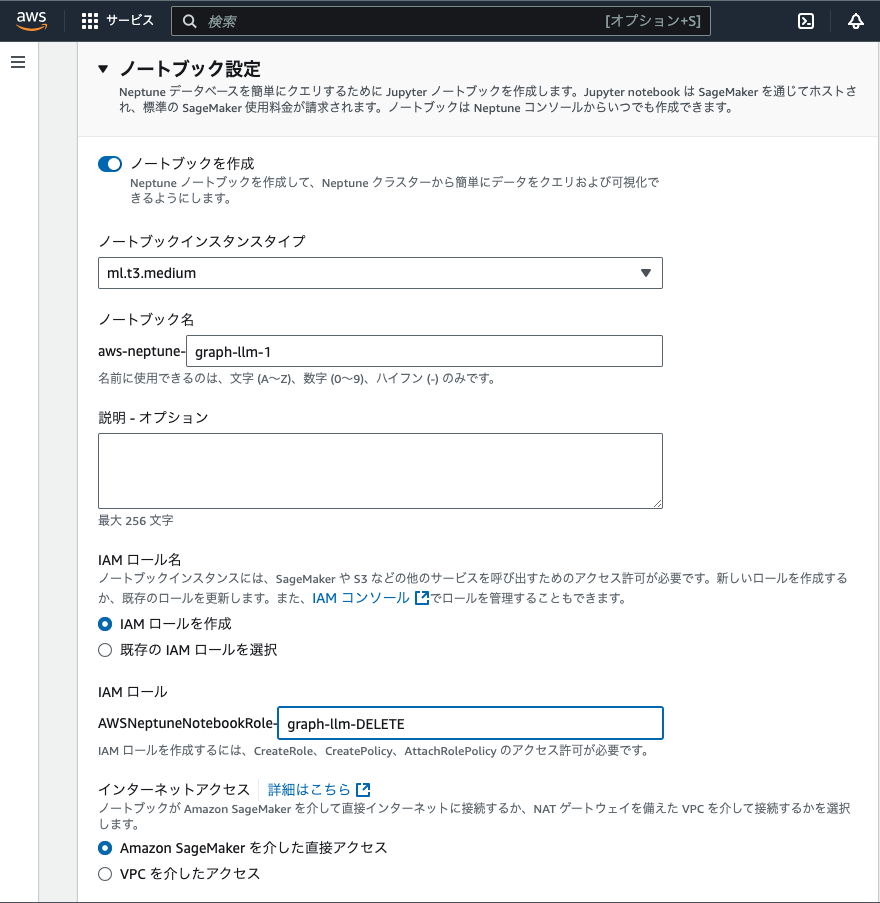
上記で指定したIAMロールが設定されていなようだった。上記のノートブック作成と同じような設定を改めて指定して、ノートブックを作成した(後述)。
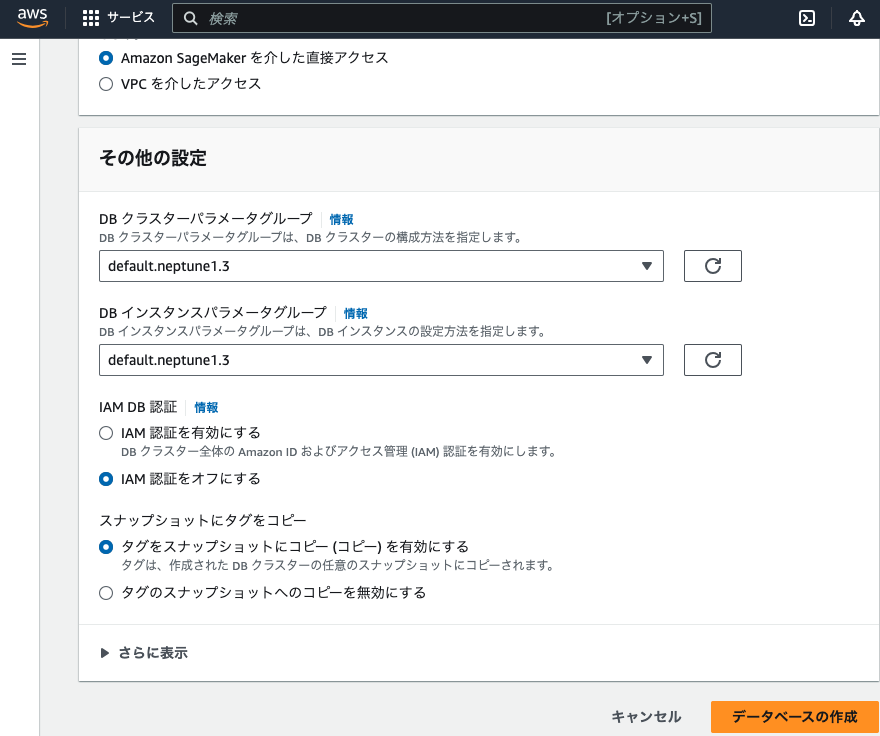
ここで、「データベースの作成」をクリックして、データベースを作成する。
データベース作成中に、以下のエラーとなった。
DBクラスター作成中にエラーが発生しましたgraph-llm-1.
The DB Subnet group doesn't meet Availability Zone (AZ) coverage requirement. Current AZ coverage: us-east-1a. Add subnet to coer at least 2 AZs.
自分が使っていたVPCでは、AZを1つしか作成していなかったのが原因のようだ。データベースの高信頼性のため複数AZを使うようだ。ここでも一つ勉強になった。この記事を参考にAZを追加した。AZ作成時は、IPアドレス(CIDR)に注意した。最初にbedrock勉強用に作っていたprivateが10.0.128.0/20だったので、10.0.192.0/20とした。
その上で、再度データベースを作成した。
この時に、「ノートブックaws-neptune-graph-llm-1を作成できませんでした」とのエラーとなったが、後で作成しようと考え、無視して進めた。
正常に作成されたとのメッセージ。
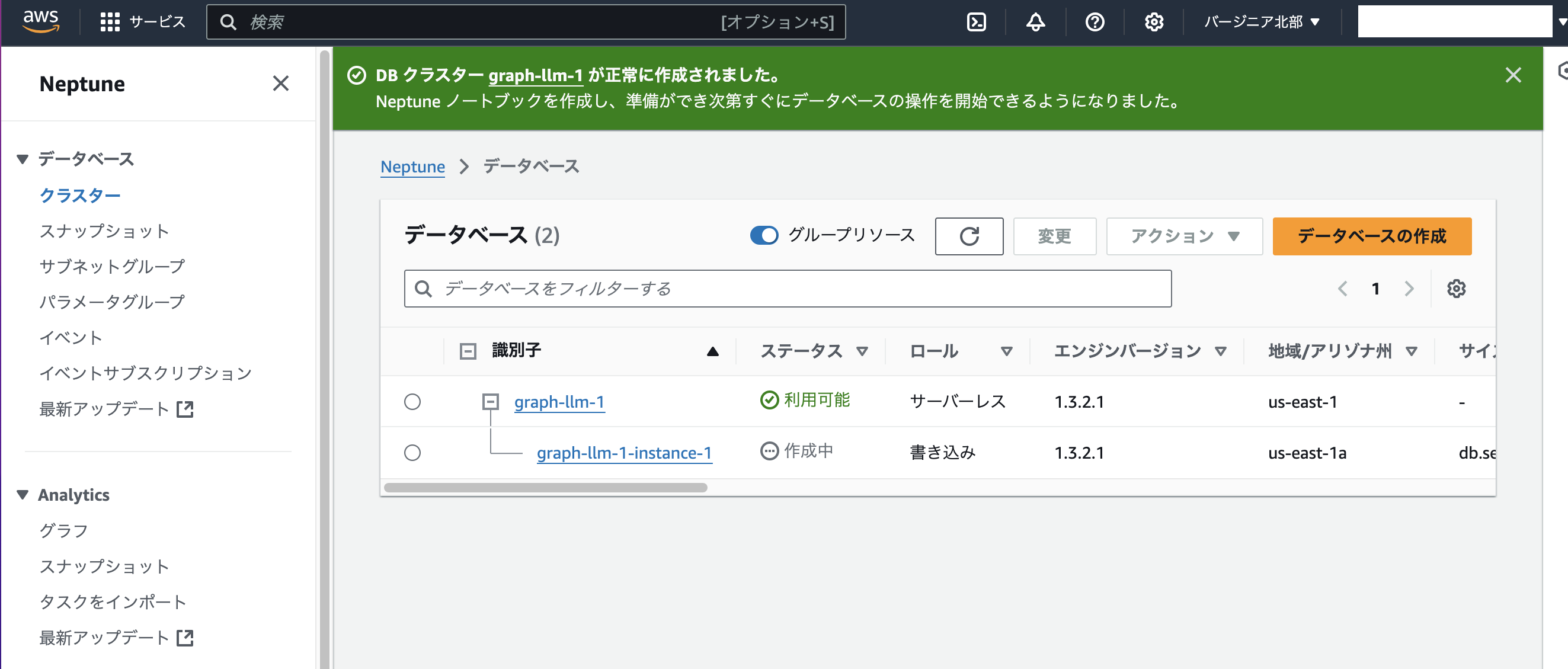
ノートブックの起動
ノートブックを作成
Neptuneのサイドメニューから、「ノートブック」を選び、既にスクリーンショットのある、「ノートブック設定」と同じような設定を行った。
ノートブックaws-neptune-graph-llm-1は作成されたが、指定したはずの「graph-llm-DELETE」ロール名はなかった。IAMロールに「AWSNeptuneNotebookRole-1730423203115」とのロール名があったので、ポリシー編集で、Bedrockを追加した。ポリシーエディタには、「bedrock:*」が作成されていた。
JupyterLabを開く
Neptuneノートブックから、上記で作成したノートブックをクリックし、「アクション」→『JupyterLabを開く」でJupyterLabを開く。
コードを試す
ここからは、通常のJupyterLabの操作によってコードを試す。
パッケージ(ライブラリ)のインストール
情報源1.では、boto3, botocore langchainをインストールしているが、自分が上記手順で構築したシステムには、既にインストールされているのでそれは不要。以下のパッケージをインストールした。
%pip install -U langchain-aws langchain-community
Neptuneグラフを準備
from langchain.graphs import NeptuneGraph
host = "graph-llm-1.cluster-ro-******.us-east-1.neptune.amazonaws.com"
port = 8182
use_https = True
graph = NeptuneGraph(host = host, port = port, use_https=use_https)
グラフデータベースにデータを投入
OpenCypher構文で記述されたテキストからグラフデータベースを作成する。
%%oc
CREATE (TheMatrix:Movie {title:'The Matrix', released:1999, tagline:'Welcome to the Real World'})
CREATE (Keanu:Person {name:'Keanu Reeves', born:1964})
・・・
今回、「%%oc」というマジックコマンドを初めて知った!
LLMを準備
from langchain_aws import BedrockLLM
from langchain.chains import NeptuneOpenCypherQAChain
modelId = 'anthropic.claude-v2'
model_kwargs = {
"max_tokens_to_sample": 512,
"temperature": 0,
"top_k": 250,
"top_p": 1,
"stop_sequences": ["\n\nHuman:"]
}
llm = Bedrock(
model_id=modelId,
model_kwargs=model_kwargs
)
情報源1.のコードから、一行目「from langchain_aws import BedrockLLM」は変更した。
グラフデータベースを使って質問に回答
chain = NeptuneOpenCypherQAChain.from_llm(llm = llm, graph=graph,verbose=True,)
chain.run("who played in Top Gun ?")
上記を実行すると、「ValueError」となる。色々と調べてみたが、今のところ原因不明。今回はここで断念。
OpenCypherクエリを実行
%%oc
MATCH (p:Person)-[:ACTED_IN]->(m:Movie {title:'Top Gun'})
RETURN p.name

Cypherクエリでは正常に結果を得られているので、グラフデータベースは出来ているようだ。
まとめ
今回は、実際にグラフデータベースの情報を使ってLLMで回答を得るところまでは出来なかったが、Neptuneをインストールしてグラフデータベースを構築するところまではできた。今後は、情報源2.や3.を参考にうまく行かなかった原因を調べると共に、動くシステムを構築していきたい。
今回、ハンズオン課題を使ってAWSを触ってみて、AWSのIAMロールなどもう少し勉強する必要があると感じた。