はじめに
昨日のこの投稿でollamaをdockerコンテナで起動し、JupyterLabからLLMを使うことについてまとめた。この投稿では、Open WebUIをコンテナで立ち上げ、それをフロントエンドとして、手元のブラウザから接続して、ollamaのLLMを使うことについてまとめる。
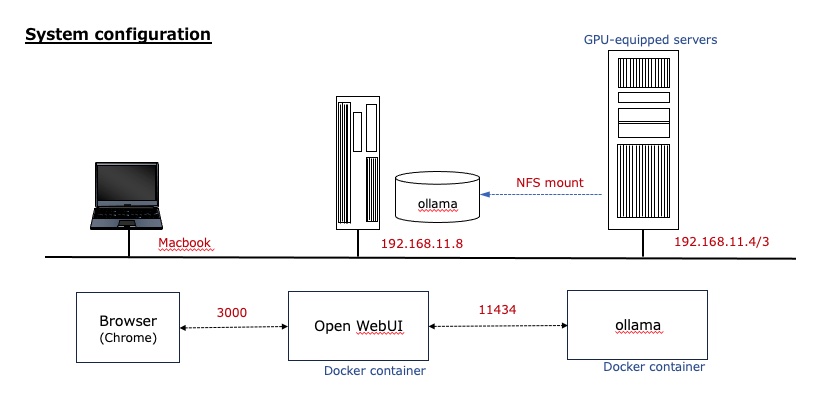
完成イメージ
次のような構成でシステムを構築した。NFSマウントについては昨日の投稿も参照されたい。
情報源
- open-webui/open-webui - Open-webUIの公式なgithubページ
- Open WebUI - Dockerでopen-webuiをはじめ方が記載.
- ローカルLLMの使用 - OllamaとOpen WebUIの連携について解説 - ollamaとopen-webuiをdockerでインストールするやり方が解説されている日本語のqiita記事。ollamaとopen-webuiをdocker-compose.ymlで一緒に(同一ホストで)起動していることが、今回自分がやろうとしている事と異なる。
Open WebUIを起動
docker-compose.ymlを作成
情報源2.を参考にして、Open WebUIを立ち上げるための設定ファイル(docker-compose.yml)を作成する。
services:
open-webui:
image: ghcr.io/open-webui/open-webui:cuda
container_name: open-webui
environment:
- OLLAMA_BASE_URL=http://192.168.11.4:11434
volumes:
- ./data:/app/backend/data
ports:
- 3000:8080
restart: always
OLLAMA_BASE_URLでollamaが動作いるホスト(実際にはそのホスト内のコンテナで動作しているが)のIPアドレスとポート番号を指定する。ここが一番のポイント。
イメージにopen-webui:cudaを使っているが、open-webui:mainでもollamaコンテナでは、GPUを使っているように見えた。(nvidia-smiでのメモリ使用量、GPU使用率から)
Open WebUIを起動
docker composeコマンドでopen-webuiを起動し、起動をdocker psコマンドで確かめた。
$ ls -l
合計 20
drwxrwxr-x 5 kenji kenji 4096 11月 23 10:44 data
-rw-rw-r-- 1 kenji kenji 264 11月 23 10:41 docker-compose.yml
-rw-rw-r-- 1 kenji kenji 264 11月 23 10:25 gamenyde_docker-compose-cuda.yml
-rw-rw-r-- 1 kenji kenji 264 11月 22 14:26 jupiter_docker-compose.yml
$ sudo docker compose up -d
$ sudo docker ps -a
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
5e3b265ccced ghcr.io/open-webui/open-webui:cuda "bash start.sh" 4 minutes ago Up 4 minutes (healthy) 0.0.0.0:3000->8080/tcp, [::]:3000->8080/tcp open-webui
ブラウザから起動
ブラウザで、「http://192.168.11.8:3000/」と入力すると、Open WebUIの起動画面が表示される。名前、メールアドレス、パスワードを入力すると、質問を受け付ける画面となる。

現在使用中のLLMが「schroneko/gemma-2-2b-jpn-it」であることが分かる。
上部の「v」の部分をクリックすると、ollamaでpullしたLLMが次のように表示され、LLMを変更することができる。

以下は、ollamaコンテナ内に入って、pullしているモデル一覧を表示させたもの。
$ sudo docker exec -it ollama /bin/bash
[sudo] kenji のパスワード:
# ollama list
NAME ID SIZE MODIFIED
neoai-8b-chat:latest ad598b8bec6a 8.5 GB 18 hours ago
llama3.2:latest a80c4f17acd5 2.0 GB 19 hours ago
hf.co/elyza/Llama-3-ELYZA-JP-8B-GGUF:latest 4d9f57e24956 4.9 GB 20 hours ago
schroneko/gemma-2-2b-jpn-it:latest fcfc848fe62a 2.8 GB 21 hours ago
# ollama ps
NAME ID SIZE PROCESSOR UNTIL
schroneko/gemma-2-2b-jpn-it:latest fcfc848fe62a 4.8 GB 100% GPU 4 minutes from now
まとめ
自分の使っている環境では、Open WebUIに接続しているブラウザ(Chrome)上での文字入力の挙動が若干変である。日本語入力(かな漢字変換)の確定の「Return」入力までの文字列で、ollamaへ問い合わせして、その結果が返される。入力欄には「Return」までに入力した確定した文字列が残っている。
また、「hf.co/elyza/Llama-3-ELYZA-JP-8B-GGUF」を使った場合、LLMからの回答が何度も繰り返されたりする現象も発生している。
半年前のこの投稿でChatbot UIを使ったシステムを構築した内容をまとめた。その時は、GPUマシンで動作するLlama-serverのコンテナ化が出来なくて苦労したが、今回は比較的簡単に、同様のシステムが構築できた。