はじめに
昨年末から定常状態の層流について、PINNsでシミュレーションしようとしていた。Cauchy stress tensor型のNS(Navier Stokes)方程式の導出が分からず、つまずいていた。一旦、Velocity-pressure型のNS方程式をベースとした支配方程式で、PINNsをコーディングした。それらしい結果が得られたので、この投稿でまとめる。
情報源
- PINN-laminar-flow - こちらのgithubに掲載されている論文とコードを参考にした。TensorFlow向けにコーディングされているので、自分が慣れ親しんでいるPytorchとは異なる部分が多く、コード全体の構成と個々の変数、定数を参考にした。元になっている論文のCauchy stress tensorが出てきたところで、理解ができず、つまずいていた。
- On Physics-Informed Deep Learning for Solving Navier-Stokes Equations - 上記1.で述べたとおり、Cauchy stress tensorが分からないので、色々とネットを調べていて見つけた情報である。論文をダウンロードして読んでみると、NS方程式には、2つの型、すなわちVelocity ~pressure (VP) formとCauchy stress tensor(ST) formがあるとのこと。こちらからは、次の情報源3.および情報源4.を参照していた。
- NSFnets (Navier-Stokes Flow nets): Physics-informed neural networks for the incompressible Navier-Stokes equations - 情報源2.からVP formとして参照されていた。こちらには、Vorticity-velocity(VV)についての記述もあった。
- Physics-informed deep learning for incompressible laminar flows - 情報源2.からST formとして参照されていた。これは、情報源1.の論文である。
- Applying Physics-Informed Neural Networks to Solve Navier–Stokes Equations for Laminar Flow around a Particle - 定常状態の層流を扱った論文。自分の方向性と合っていたので参考になった。特に、損失関数の合計を求める箇所で、計算領域と境界条件のサンプルポイント数の違いから、重みを付けているとの記述は参考になった。
物理的背景
支配方程式の導出
連続の方程式とNS方程式(Navier Stokes Equations)は、次のとおり。 $$ \frac{\partial \rho}{\partial t} +\nabla \cdot (\rho \boldsymbol{v}) =0 \tag{1} $$
$$ \rho \left( \frac{\partial \boldsymbol{v}}{\partial t} +(\boldsymbol{v}\cdot \nabla)\boldsymbol{v} \right) = -\nabla p+ \mu\Delta \boldsymbol{v} + \rho\boldsymbol{g} \tag{2} $$
ここで、$\rho$は流体の密度、$\boldsymbol{v}(\boldsymbol{r},t)$は流体の速度、$p(\boldsymbol{r},t)$は流体にかかる圧力、$\mu$は粘性係数、$\boldsymbol{g}$は外力である。NS方程式の各項の意味は次のとおり。左辺の第1項は時間微分項、第2項は移流項(対流項)。右辺の第1項は圧力項、第2項は粘性項(拡散項)、第3項は外力項である。
ここでは、非圧縮流体の定常状態を扱うことにするので、連続の方程式とNS方程式は、次のようになる。 $$ \nabla \cdot \boldsymbol{v} = 0 \tag{3} $$ NS方程式(2)において、定常状態を考えると時間微分項は消え、外力の無い2次元を考えると外力項が消え、左右を入れ替えると、次のように書ける。 $$ -\nabla p + \mu \Delta \boldsymbol{v} = \rho(\boldsymbol{v}\cdot \nabla)\boldsymbol{v} \tag{4} $$ 上記の式(3)(4)を2次元の座標$(x, y)$、速度成分$(u,v)$を使って表すと次のとおり。 $$ \frac{\partial u}{\partial x} + \frac{\partial v}{\partial y} = 0 \tag{5} $$
$$ -\frac{\partial p}{\partial x} + \mu \left(\frac{\partial^2 u}{\partial x^2}+\frac{\partial^2 u}{\partial y^2}\right) = \rho \left(u\frac{\partial u}{\partial x}+v\frac{\partial u}{\partial y}\right) \tag{6} $$
$$ -\frac{\partial p}{\partial y} + \mu \left(\frac{\partial^2 v}{\partial x^2}+\frac{\partial^2 v}{\partial y^2}\right) = \rho \left(u\frac{\partial v}{\partial x}+v\frac{\partial v}{\partial y}\right) \tag{7} $$
上記の式(5)(6)(7)が支配方程式である。なお式(6)(7)においては、左辺を右辺に移行し$=0$の形式を支配方程式としている。
Navier Stokes方程式の2つの型
参考までに、NS方程式のVelocity-pressure(VP)型とCauchy stress tensor(ST)型について、以下にまとめる。情報源2.からの引用である。
Velocity-presssure(VP) form
こちらは、以下の通り見慣れた表記である。 $$ \rho(\boldsymbol{u}\cdot\nabla)\boldsymbol{u} = -\nabla p + \mu\nabla^2\boldsymbol{u} \tag{8} $$
$$ \nabla \cdot \boldsymbol{u} = 0 \tag{9} $$
$$ \boldsymbol{u} = \boldsymbol{u}_{\Gamma} \qquad in , \Gamma_D \tag{10} $$
$$ \partial_n \boldsymbol{u} = 0 \qquad in , \Gamma_N \tag{11} $$
ここで、$\Gamma_D$と$\Gamma_N$は、ディリクレ境界条件(Dirichlet boundary condition)とノイマン境界条件(Neumann boundary condition)を表す。
Cauchy stress tensor(ST) form
こちらは、Cauchy stress tensorである$\sigma$を介して表現されている。導出については理解できていない。 $$ \rho(\boldsymbol{u}\cdot\nabla)\boldsymbol{u} = -\nabla \cdot \sigma \tag{12} $$
$$ \sigma = -p\boldsymbol{I}+\mu \left(\nabla\boldsymbol{u}+\nabla\boldsymbol{u}^T \right) \tag{13} $$
$$ \nabla \cdot \boldsymbol{u} = 0 \tag{14} $$
$$ \boldsymbol{u} = \boldsymbol{u}_{\Gamma} \qquad in , \Gamma_D \tag{15} $$
$$ \partial_n \boldsymbol{u} = 0 \qquad in , \Gamma_N \tag{16} $$
コード
必要なパッケージをimport、GPUを使っていることを確認
import numpy as np
import torch
import torch.nn as nn
import torch.nn.functional as F
from torch import optim
from torch.optim import lr_scheduler
import matplotlib.pyplot as plt
from pyDOE import lhs # Latin Hypercube Sampling (LHS
# run on cuda if possible
device = 'cuda' if torch.cuda.is_available() else 'cpu'
print("Running on", device)
関数を定義
# Remove points inside the cylinder from collocation points
# Find the distance between the center of the cylinder (xc, yc) and a point,
# and delete anything less than the cylinder radius (r).
def Remove_inCylinder(coor, xc, yc, r):
distance = np.array([((xy[0] - xc)**2 + (xy[1]-yc)**2)**0.5 for xy in coor])
return coor[distance > r, :]
上記の関数は、円柱の内部の点を削除する関数である。
# Differentiation by pytorch
# return dy/dx
def gradients(y, x):
return torch.autograd.grad(y,
x,
grad_outputs=torch.ones_like(y),
create_graph=True,
)[0]
上記の関数は、torchの関数を使って、微分(偏微分)を行う関数である。次のモデルの関数であるnet_f()の見通しを良くするために関数として定義した。
全結合層のネットワーク・クラスを作成
# define u_NN class
class u_NN(nn.Module):
def __init__(self, n_input, n_output, n_hiddens=[32,64,128,128,64,32]):
super().__init__()
self.activation = nn.Tanh()
self.input_layer = nn.Linear(n_input, n_hiddens[0])
self.hidden_layers = nn.ModuleList(
[nn.Linear(n_hiddens[i], n_hiddens[i+1]) for i in range(len(n_hiddens)-1)]
)
self.output_layer = nn.Linear(n_hiddens[-1], n_output)
def forward(self, x):
x = self.activation(self.input_layer(x))
for layer in self.hidden_layers:
x = self.activation(layer(x))
x = self.output_layer(x)
return x
def neural_net(self, x, y):
inputs = torch.cat([x, y], dim=1)
outputs = self.forward(inputs)
u = outputs[:, 0:1]
v = outputs[:, 1:2]
p = outputs[:, 2:3]
return u, v, p
def net_f(self, x, y):
x.requires_grad = True
y.requires_grad = True
u, v, p = self.neural_net(x, y)
u_x = gradients(u, x)
v_y = gradients(v, y)
f1 = u_x + v_y
p_x = gradients(p, x)
u_y = gradients(u, y)
u_xx = gradients(u_x, x)
u_yy = gradients(u_y, y)
f2 = p_x - mu*(u_xx + u_yy) + rho*(u*u_x + v*u_y)
p_y = gradients(p, y)
v_x = gradients(v, x)
v_xx = gradients(v_x, x)
v_yy = gradients(v_y, y)
f3 = p_y - mu*(v_xx + v_yy) + rho*(u*v_x + v*v_y)
return f1, f2, f3
問題領域(変数、定数)を定義
wall_samples = 441
inlet_samples = 201
outlet_samples = 201
# define wall(floor, celling)
# celling: (0, 0.41)-(1.1, 0.41)
# floor: (0, 0)-(1.1, 0)
CEILING = [0.0, 0.41] + [1.1, 0.0] * lhs(2, wall_samples)
FLOOR = [0.0, 0.0] + [1.1, 0.0] * lhs(2, wall_samples)
# define inlet flow
# u(0,y) = 4 * U_max * (H - y) * y / H^2
# It is a (convex upward) quadratic curve
# passing through 0 and H on the y-axis.
U_max = 1.0
INLET = [0.0, 0.0] + [0.0, 0.41] * lhs(2, inlet_samples)
y_INLET = INLET[:, 1:2]
u_INLET = 4 * U_max * y_INLET * (0.41 - y_INLET) / (0.41**2)
v_INLET = 0 * y_INLET
INLET = np.concatenate((INLET, u_INLET, v_INLET), 1)
# OUTLET
OUTLET = [1.1, 0.0] + [0.0, 0.41] * lhs(2, outlet_samples)
# Define cylinder surface
surface_samples = 251
r = 0.05
theta = [0.0] + (2*np.pi) * lhs(1, surface_samples)
x_CYLD = np.multiply(r, np.cos(theta)) + 0.2
y_CYLD = np.multiply(r, np.sin(theta)) + 0.2
CYLD = np.concatenate((x_CYLD, y_CYLD), 1)
# Put together walls (floors, ceilings, cylinder surfaces)
WALL = np.concatenate((CYLD, CEILING, FLOOR), 0)
# Define collocation point (See collocation method) for PINNs
coll_samples = 10000 # numper of collocation point
ref_samples = 1000 # number of refine point (around the cylinder)
lb = np.array([0, 0])
ub = np.array([1.1, 0.41])
XY_c = lb + (ub - lb) * lhs(2, coll_samples)
XY_c_refine = [0.1, 0.1] + [0.2, 0.2] * lhs(2, ref_samples)
XY_c = np.concatenate((XY_c, XY_c_refine), 0)
XY_c = Remove_inCylinder(XY_c, xc=0.2, yc=0.2, r=0.05)
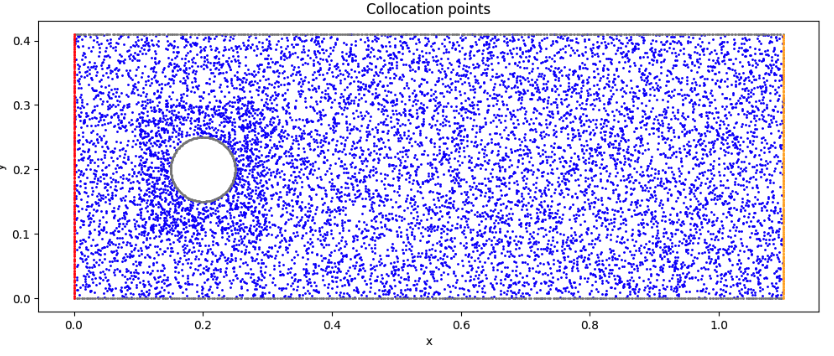
collocation pointを可視化
# Visualize the collocation points
fig, ax = plt.subplots(figsize=(12,8))
ax.set_aspect('equal')
ax.scatter(XY_c[:, 0:1], XY_c[:, 1:2], marker='o', color='blue', s=1)
ax.scatter(WALL[:, 0:1], WALL[:, 1:2], marker='o', color= 'gray', s=1)
ax.scatter(OUTLET[:, 0:1], OUTLET[:, 1:2], marker='o', color='orange', s=1)
ax.scatter(INLET[:, 0:1], INLET[:, 1:2], marker='o', color='red', s=1)
ax.set_title('Collocation points')
ax.set_xlabel('x')
ax.set_ylabel('y')
plt.show()
モデルを作成
# Create a Model
# Input: (x, y)
# Output: (u, v, p)
model = u_NN(2, 3).to(device)
print(model)
学習に使う変数をtensor化
# Define collocation, INLET, OUTLET, and WALL variables as torch.tensor
x_c = torch.tensor(XY_c[:, 0:1], device=device, dtype=torch.float32)
y_c = torch.tensor(XY_c[:, 1:2], device=device, dtype=torch.float32)
x_INLET = torch.tensor(INLET[:, 0:1], device=device, dtype=torch.float32)
y_INLET = torch.tensor(INLET[:, 1:2], device=device, dtype=torch.float32)
u_INLET = torch.tensor(INLET[:, 2:3], device=device, dtype=torch.float32)
v_INLET = torch.tensor(INLET[:, 3:4], device=device, dtype=torch.float32)
x_OUTLET = torch.tensor(OUTLET[:, 0:1], device=device, dtype=torch.float32)
y_OUTLET = torch.tensor(OUTLET[:, 1:2], device=device, dtype=torch.float32)
x_WALL = torch.tensor(WALL[:, 0:1], device=device, dtype=torch.float32)
y_WALL = torch.tensor(WALL[:, 1:2], device=device, dtype=torch.float32)
mu = 0.02
rho = 1.0
損失関数、最適化関数を定義
# Loss function: Mean Square Error
loss_func = nn.MSELoss()
# Optimizer: Adam(Adaptive moment estimation)
optimizer = optim.Adam(model.parameters(), lr=0.001)
# scheduler = lr_scheduler.ExponentialLR(optimizer, gamma=0.98)
loss_func()は今回使っていない。全てtorch.mean()で処理している。
学習ループ
# learning Loop
num_epoch = 8000 # epoch count
Epoch = []
Loss_f1 = []
Loss_f2 = []
Loss_f3 = []
Loss_f = []
Loss_t = []
Loss_WALL = []
Loss_INLET = []
Loss_OUTLET = []
for i in range(num_epoch):
if i == 0:
print("Epoch \t Loss_f1 \t Loss_f2 \t Loss_f3 \t Loss_f \t Loss_WALL \t Loss_INLET \t Loss_OUTLET")
optimizer.zero_grad()
f1, f2, f3 = model.net_f(x_c, y_c)
loss_f1 = torch.mean(f1**2)
loss_f2 = torch.mean(f2**2)
loss_f3 = torch.mean(f3**2)
loss_f = loss_f1 + loss_f2 + loss_f3
u_wall, v_wall, _ = model.neural_net(x_WALL, y_WALL)
loss_WALL = torch.mean(u_wall**2) + torch.mean(v_wall**2)
u_inlet, v_inlet, _ = model.neural_net(x_INLET, y_INLET)
loss_INLET = torch.mean((u_inlet - u_INLET)**2) + torch.mean((v_inlet - v_INLET)**2)
_, _, p_outlet = model.neural_net(x_OUTLET, y_OUTLET)
loss_OUTLET = torch.mean(p_outlet**2)
loss_t = loss_f + 2*(loss_WALL + loss_INLET + loss_OUTLET)
loss_t.backward()
optimizer.step()
if i % 100 == 0:
Epoch.append(i)
Loss_f1.append(loss_f1.detach().cpu().numpy())
Loss_f2.append(loss_f2.detach().cpu().numpy())
Loss_f3.append(loss_f3.detach().cpu().numpy())
Loss_f.append(loss_f.detach().cpu().numpy())
Loss_t.append(loss_t.detach().cpu().numpy())
Loss_WALL.append(loss_WALL.detach().cpu().numpy())
Loss_INLET.append(loss_INLET.detach().cpu().numpy())
Loss_OUTLET.append(loss_OUTLET.detach().cpu().numpy())
if i % 1000 == 0:
print(i, "\t",
format(loss_f1.detach().cpu().numpy(), ".4E"), "\t",
format(loss_f2.detach().cpu().numpy(), ".4E"), "\t",
format(loss_f3.detach().cpu().numpy(), ".4E"), "\t",
format(loss_f.detach().cpu().numpy(), ".4E"), "\t",
format(loss_WALL.detach().cpu().numpy(), ".4E"), "\t",
format(loss_INLET.detach().cpu().numpy(), ".4E"), "\t",
format(loss_OUTLET.detach().cpu().numpy(), ".4E"), "\t",
)
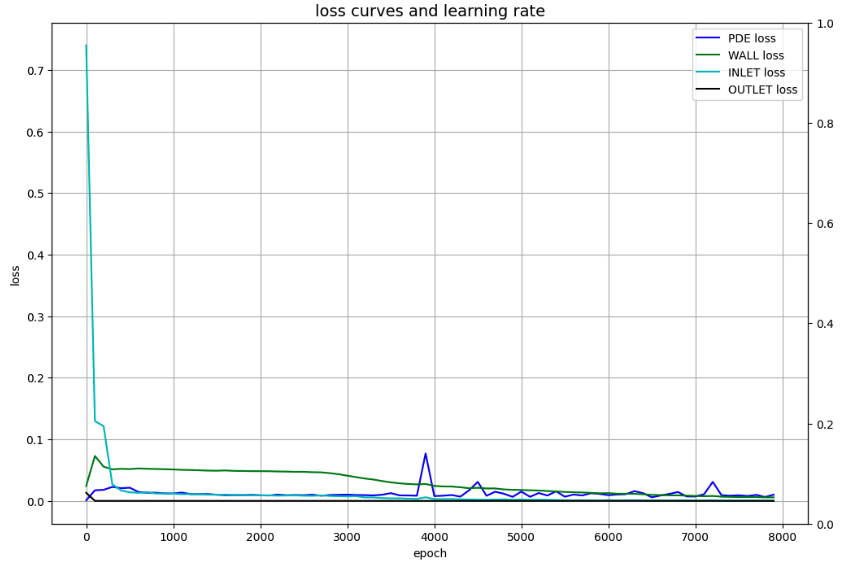
損失を可視化
# Draw loss curves
fig, ax1 = plt.subplots(figsize=(12, 8))
ax2 = ax1.twinx()
ax1.plot(Epoch, Loss_f, c='b', label='PDE loss')
ax1.plot(Epoch, Loss_WALL, c='g', label='WALL loss')
ax1.plot(Epoch, Loss_INLET, c='c', label='INLET loss')
ax1.plot(Epoch, Loss_OUTLET, c='k', label='OUTLET loss')
ax1.set_xlabel('epoch')
ax1.set_ylabel('loss')
ax1.set_title('loss curves and learning rate', fontsize='14')
ax1.grid()
ax1.legend()
plt.show()
速度場、圧力場を表示
# Using the learned model,
# find u,v,p in the form of collocation coordinates of x,y
x_collo = np.linspace(0, 1.1, 251)
y_collo = np.linspace(0, 0.41, 101)
X, Y = np.meshgrid(x_collo, y_collo)
# Remove cylinder internals
X = X.flatten()[:, None]
Y = Y.flatten()[:, None]
dst = ((X - 0.2)**2 + (Y - 0.2)**2)**0.5
X = X[dst >= 0.05]
Y = Y[dst >= 0.05]
# Convert to tensor
x_collo = torch.tensor(X.flatten()[:, None], device=device, dtype=torch.float32)
y_collo = torch.tensor(Y.flatten()[:, None], device=device, dtype=torch.float32)
# Predicts speed and pressure
u_pred, v_pred, p_pred = model.neural_net(x_collo, y_collo)
u_pred = u_pred.to("cpu").detach().numpy()
v_pred = v_pred.to("cpu").detach().numpy()
p_pred = p_pred.to("cpu").detach().numpy()
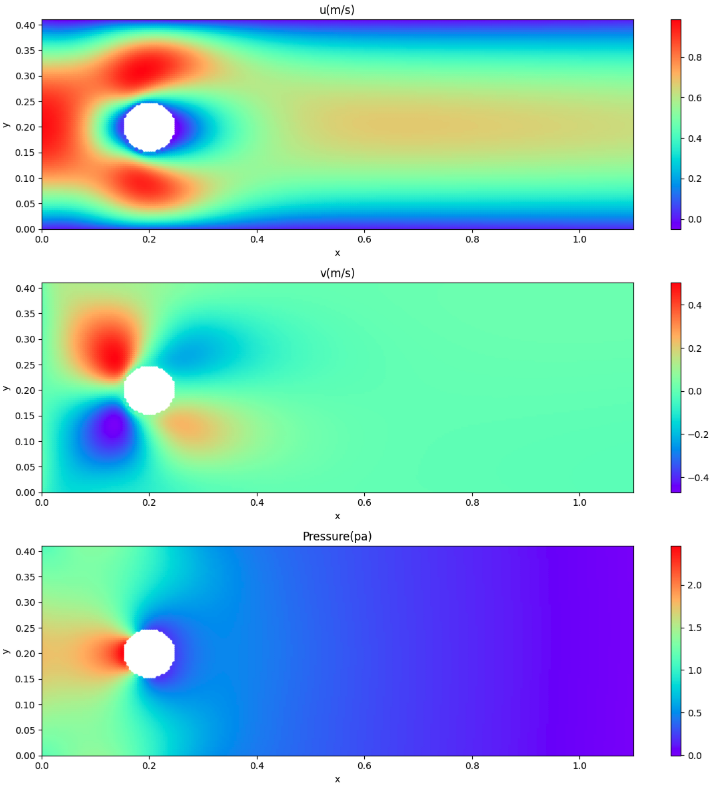
可視化はcontourf()で等高線表示にしようと考えていたが、今回のように円柱部分をくり抜いくと、2次元に変換するところが上手くいかないので、scatter()で表示するようにした。
# Visualize predicted velocity, pressure
alpha = 1.0
cmap = 'rainbow'
marker= 'o'
s = 20
fig = plt.figure(figsize=(12,12))
ax1 = fig.add_subplot(3, 1, 1)
cp = ax1.scatter(X, Y, c=u_pred, alpha=alpha, edgecolors='none', cmap=cmap, marker=marker, s=s)
fig.colorbar(cp)
ax1.set_xlim([0, 1.1])
ax1.set_ylim([0, 0.41])
ax1.set_title('u(m/s)')
ax1.set_xlabel('x')
ax1.set_ylabel('y')
ax2 = fig.add_subplot(3, 1, 2)
cp = ax2.scatter(X, Y, c=v_pred, alpha=alpha, edgecolors='none', cmap=cmap, marker='o', s=s)
fig.colorbar(cp)
ax2.set_xlim([0, 1.1])
ax2.set_ylim([0, 0.41])
ax2.set_title('v(m/s)')
ax2.set_xlabel('x')
ax2.set_ylabel('y')
ax3 = fig.add_subplot(3, 1, 3)
cp = ax3.scatter(X, Y, c=p_pred, alpha=alpha, edgecolors='none', cmap=cmap, marker='o', s=s)
fig.colorbar(cp)
ax3.set_xlim([0, 1.1])
ax3.set_ylim([0, 0.41])
ax3.set_title('Pressure(pa)')
ax3.set_xlabel('x')
ax3.set_ylabel('y')
plt.tight_layout()
plt.show()
可視化結果
初期状態(collocation points)
学習状況
速度場、圧力場を推論
まとめ
PINNsにより対象領域を推論した結果を可視化すると、情報源で見るような速度場・圧力場の結果が得られたので、ここにまとめた。従って、得られた結果(数値)を他の方式による結果と比較しての考察は出来ていない。比較すべき他の方式の一つとして、先日来取り組んでいたOpenFoamを考えている。
今回は定常状態を仮定したので、変数に時間を含んでいない。情報源1.にも時間を含んだ問題設定もあるので、次回はそちらを試してみたい。更には、カルマン渦の生成までPINNsでシミュレーションしたいと考えている。